In the era of large-scale data, organizations are collecting vast amounts of information from various sources. However, raw data is often unstructured and messy, making it challenging to extract valuable insights. Data transformation tools are essential for cleaning, organizing, and preparing data for analysis. Amazon Web Services (AWS) offers two powerful tools, AWS Glue and Amazon Athena, to simplify and streamline this process.
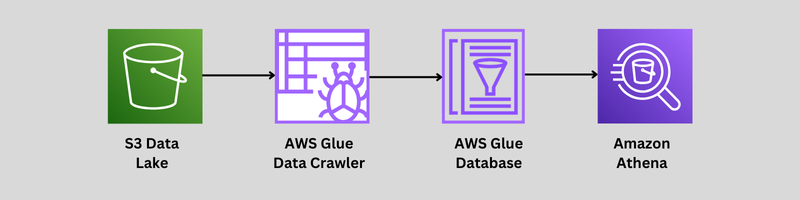
This blog explores how these tools work and how they can be used together for seamless data transformation and querying.
Why Do We Need Data Transformation Tools?
Raw data is rarely ready for analysis. It may include duplicate entries, missing values, or inconsistent formats. Data transformation tools help organizations:
- Clean and enrich data for accuracy.
- Integrate data from multiple sources into a unified format.
- Prepare data for advanced analytics, reporting, and machine learning.
- Reduce the manual effort, ensuring efficient workflows.
Overview of AWS Glue
AWS Glue is a fully managed Extract, Transform, Load (ETL) service designed to automate the data transformation process. Whether you’re preparing data for analytics or machine learning, AWS Glue provides the tools to clean, transform, and organize your datasets efficiently.
What is AWS Glue?
AWS Glue is an ETL service that simplifies data preparation by automating tasks such as schema discovery, data cleaning, and transformations.
Key Features
- Serverless Architecture: No infrastructure to manage—AWS Glue scales automatically based on your data.
- Data Catalog: A central metadata repository to store schema and table information for data sources.
- Built-In Transformations: Ready-to-use transformations for cleaning and preparing data.
- Integration with AWS Services: Works seamlessly with Amazon S3, Redshift, and Athena.
Use Cases and Benefits
- Data Integration: Consolidate data from multiple sources into a unified repository.
- Machine Learning Preparation: Prepare training datasets for ML models.
- Real-Time Analytics: Transform streaming data for real-time insights.
- Cost-Efficient ETL: Save time and reduce operational costs with automated workflows.
What Are Crawlers?
AWS Glue Crawlers are a core feature that automates schema discovery and metadata creation. They scan your data sources, infer the schema, and populate the AWS Glue Data Catalog.
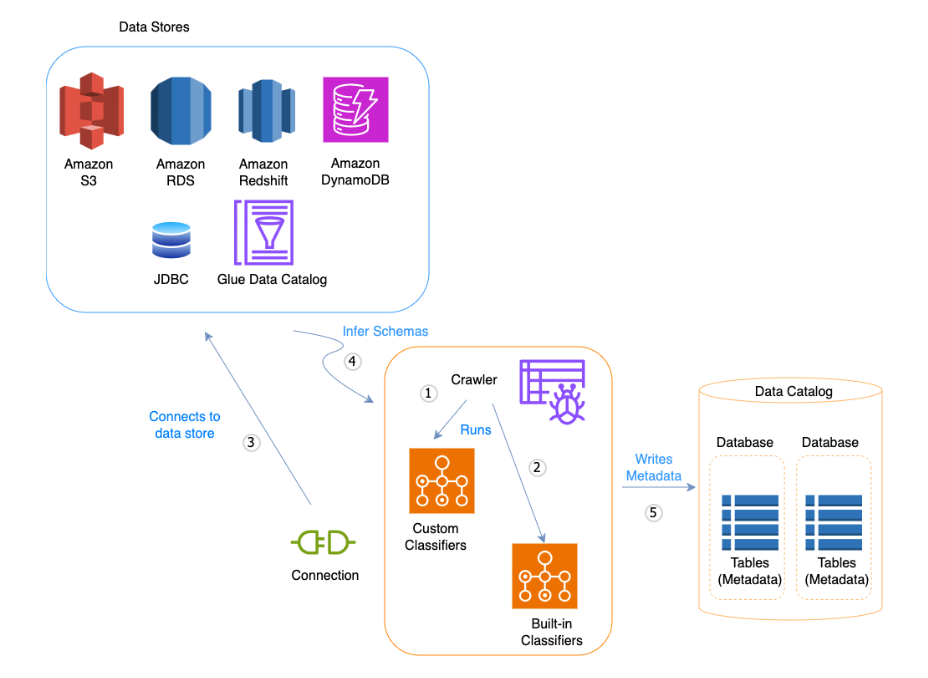
Image Ref: https://docs.aws.amazon.com/glue/latest/dg/add-crawler.html
Crawlers automate the process of discovering datasets, their structure, and their schema, enabling seamless integration with analytics tools.
What is Amazon Athena?
Amazon Athena is a serverless interactive query service that enables you to analyze data directly from Amazon S3 using SQL.
Athena simplifies data querying by eliminating the need for a database setup or data movement. It allows you to query raw or transformed data stored in S3, making it ideal for ad-hoc analytics.
Why Athena?
- Ad-Hoc Data Analysis: Quickly query log files, clickstream data, or IoT sensor outputs stored in S3.
- Reporting and Dashboards: Power BI, Tableau, or Quicksight can directly integrate with Athena for visualizations.
- Cost-Efficient Analytics: Pay only for the queries you run, reducing analytics costs.
Demo: Practical example of generating a data catalog
Example: We’ll demonstrate how AWS Glue Crawlers automatically detect and catalog the schema of a dataset (CSV file) stored in Amazon S3. Using the catalog, Amazon Athena simplifies SQL-based querying directly from S3.
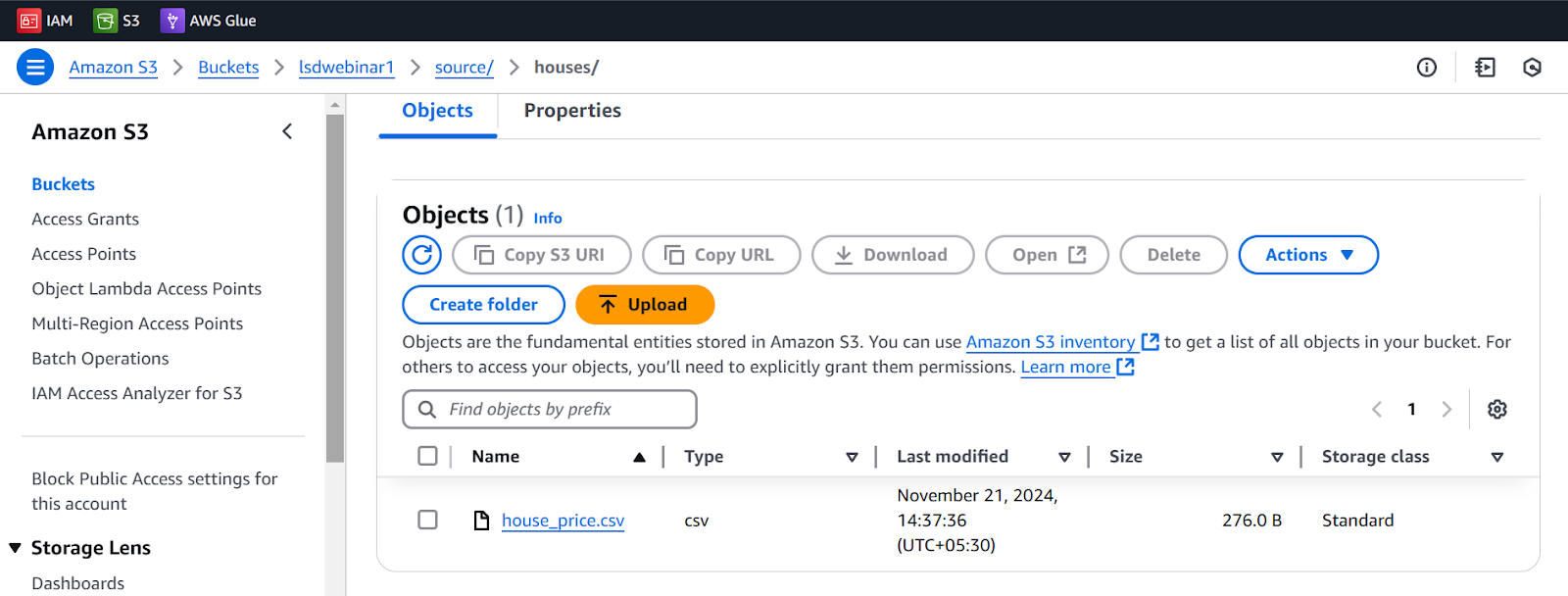
Create an S3 bucket
Our first step is to create an S3 bucket to store our CSV file.
- Search S3 bucket from Amazon console & create bucket (lsdwebinar1)
- Create folders:
- source
- houses
- source
- Add house_price.csv file in sources/houses folder
Now, set up the ETL process using AWS Glue. We will use Crawler to create a table in DB automatically from the S3 bucket data.
AWS Crawlers
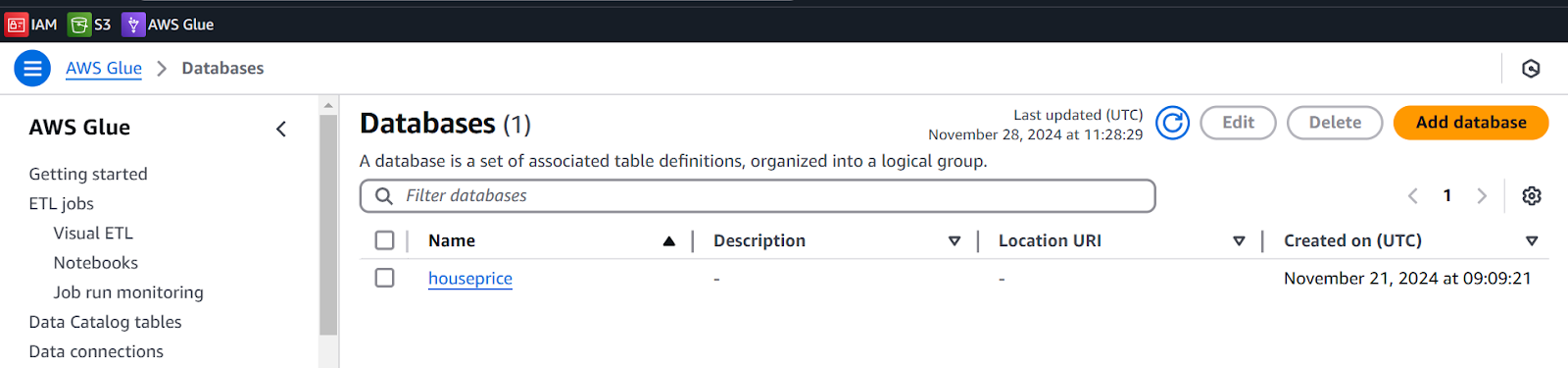
First, We will create a Database to store the data catalog.
- Navigate to Database in AWS Glue.
- Add Database (houseprice).
No Tables in a Database. now we will set Crawler.
- Navigate to Crawler in AWS Glue
- Crawler is listed under a Data Catalog
- Create a Crawler and follow the steps
- Give name to the Crawler(house-price)
- Add an S3 data source (What should be crawled? Select that location)
- Configure security settings
- Create a new IAM role (AWSGlueServiceRole-glue-carwler-test)
- Set output and scheduling
- Choose target Database (houseprice)
- Add table prefix (data_)
- Schedule(on demand), We can schedule Crawler to rerun automatically.
- Review and Create
- Create Crawler
Next, we will view our Crawler.
View Crawlers from AWS Glue
Navigate to the Crawlers to see the list of Crawlers. We can see our Crawler is in ready state.
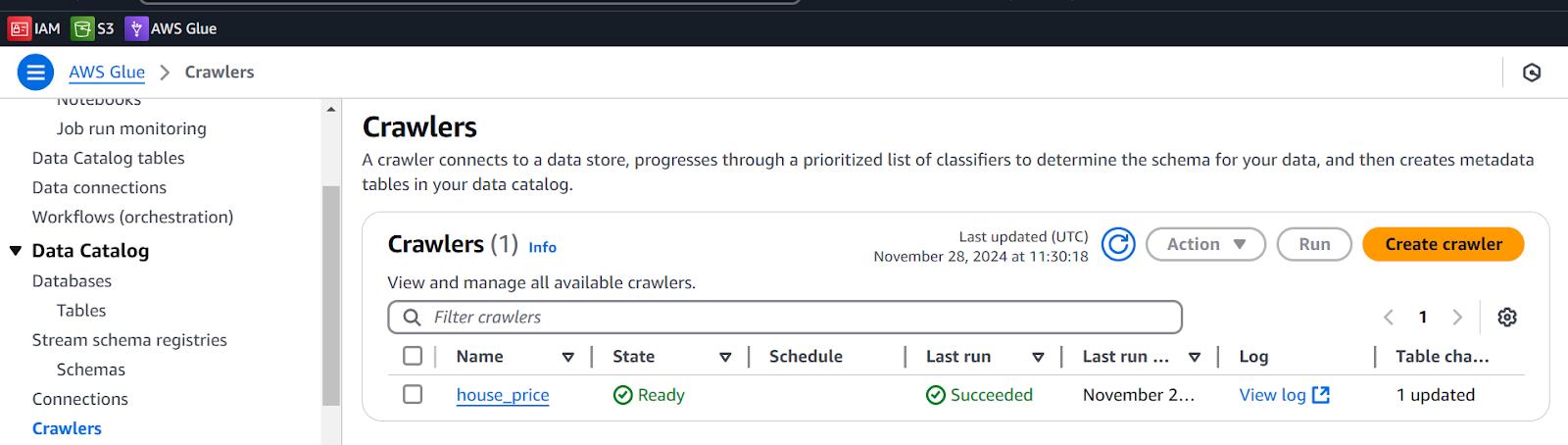
We are good to go!!!
Run the Crawler
We will run the Crawler to create a data catalog of our source.
- Select house_price Crawler and Run Crawler
After a few seconds it will be in the Completed stage.
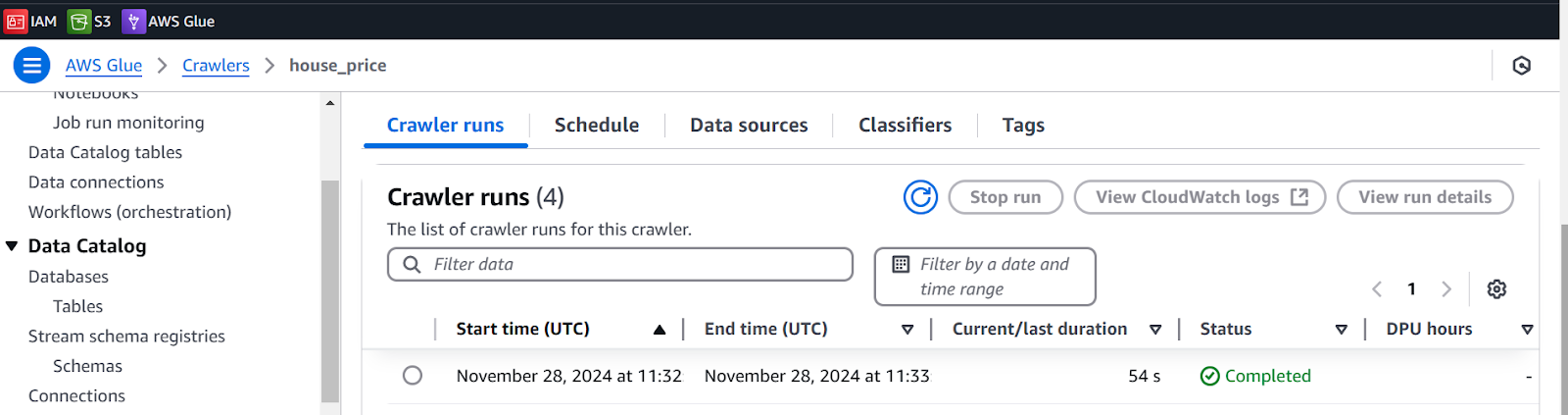
Next, See the result in a Database.
View Table in Database
- Go to the Database and Refresh the page. We will get a table over here.
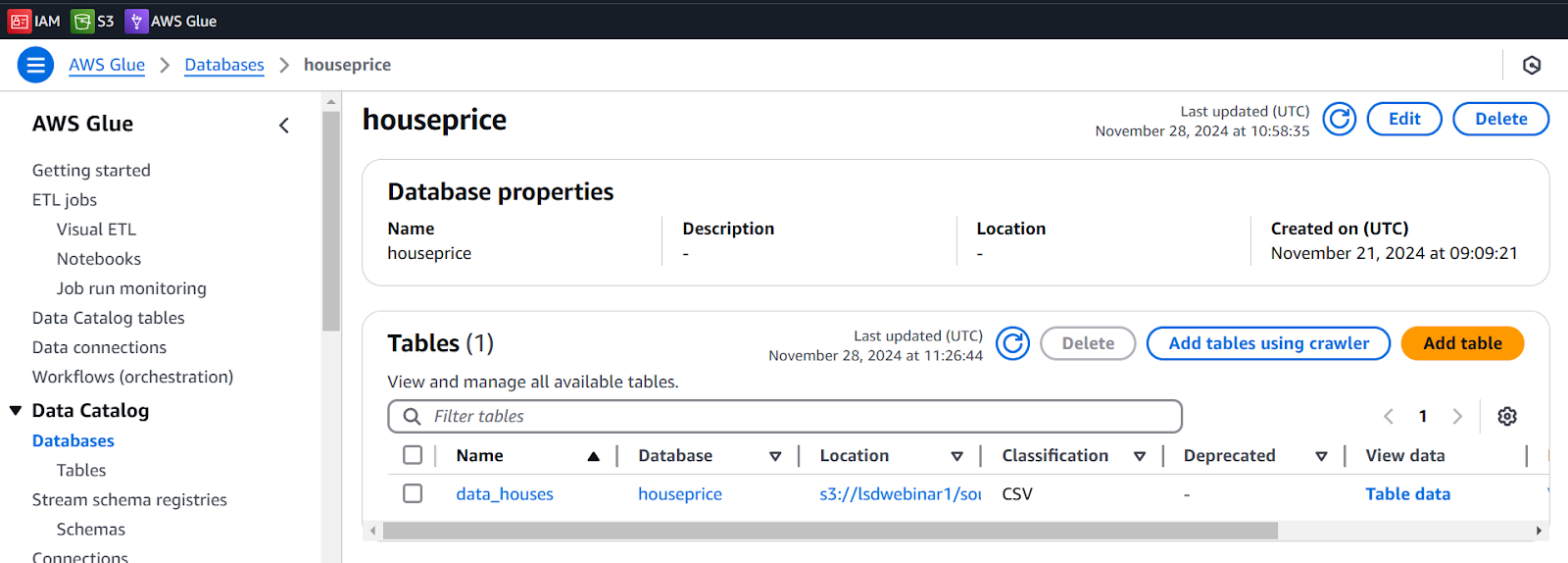
- Click on data_houses Table, we can see the structure is created.
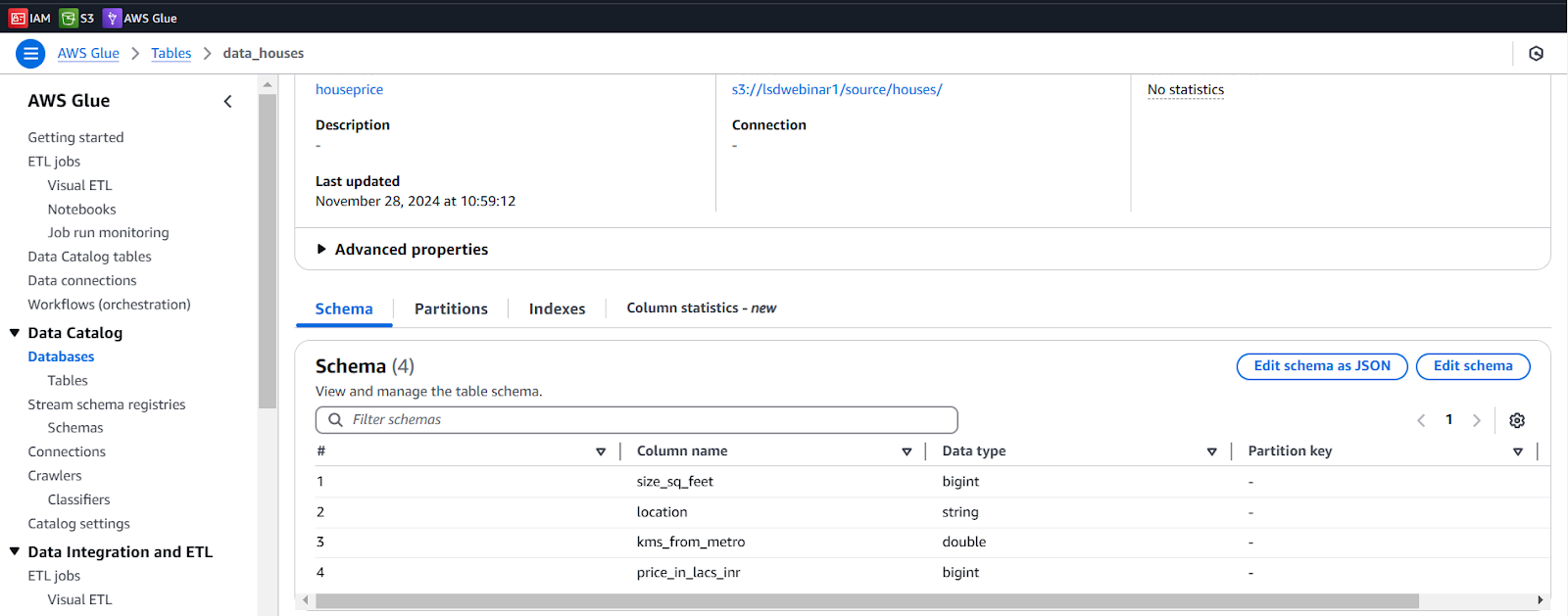
To view the actual data in the Table,
- Go back to Database (houseprice)
- Click on View data Table data.
- Click on Proceed, it will take you to the Athena.
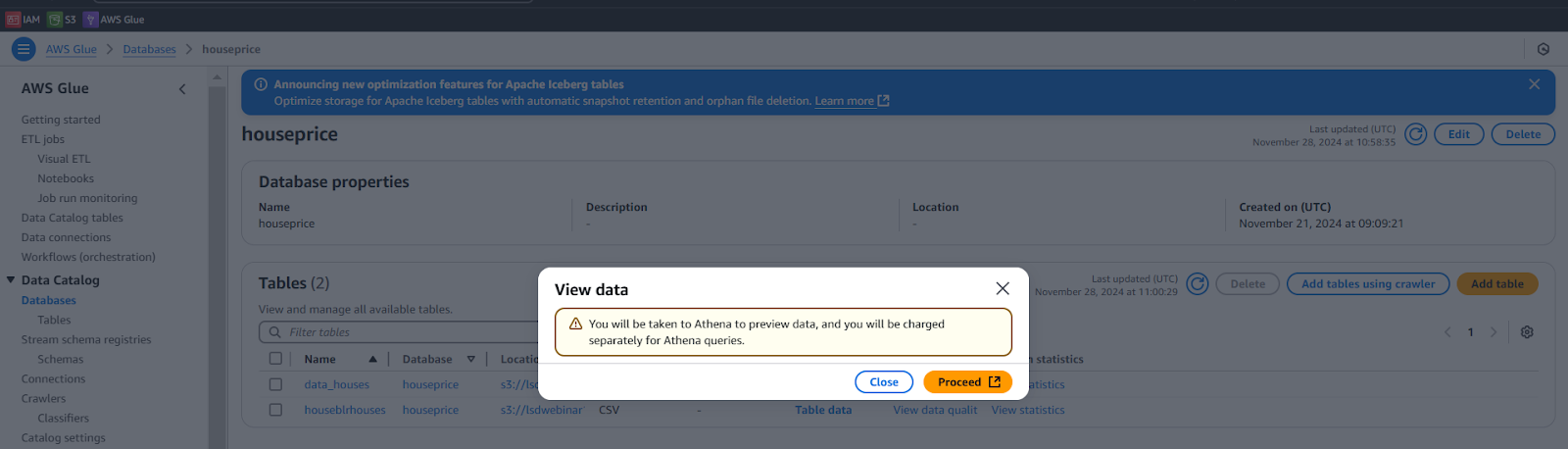
Athena: To perform a query on table data
To View a Table data in Athena we need to set a query result location.
- Go to Query editor Settings
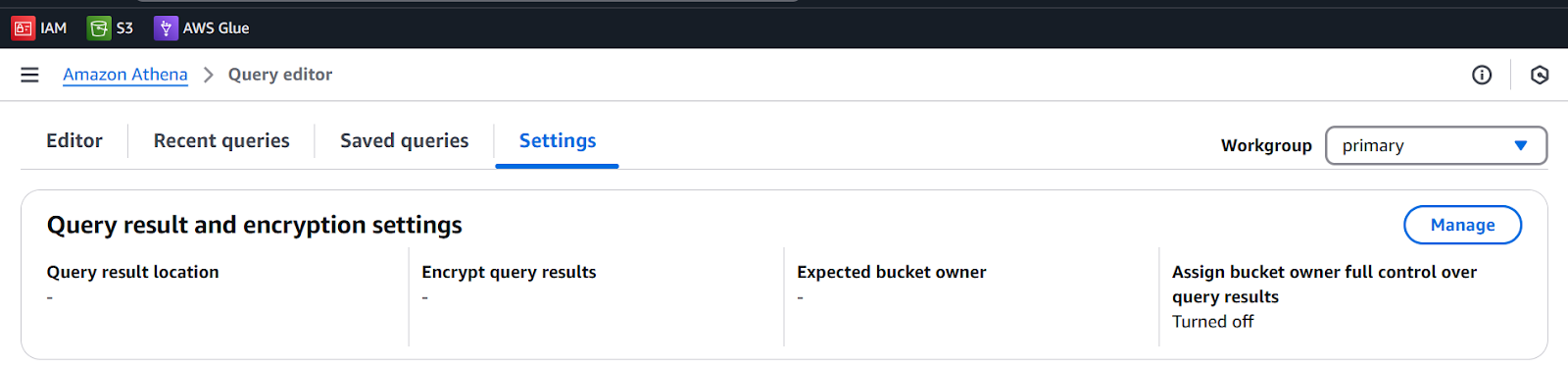
- Click on Manage
- Choose S3 data set
- Keep other things default and Save the settings.
OR
Without viewing Table data from the Database. We can search Athena from the Amazon console,
- Go to Amazon Athena
- Select Query editor
- Select data source: AwsDataCatalog
- Select database houseprice
- Tables are available here
Now, we are ready to perform Query.
Query from Athena
Run your query,
- Go to Editor
- Query: SELECT * FROM “AwsDataCatalog”.”houseprice”.”data_houses”;
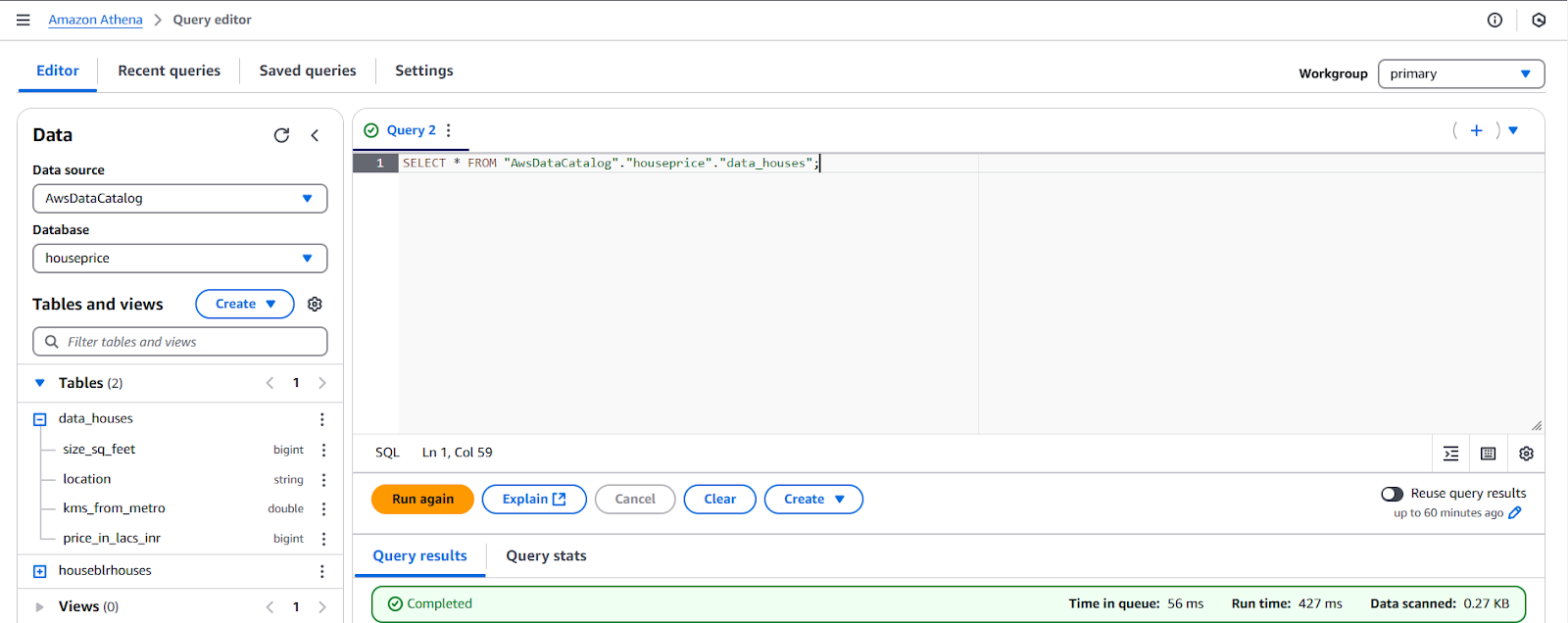
- Run a Query.
We can view the data of our house_price.csv file in proper format,
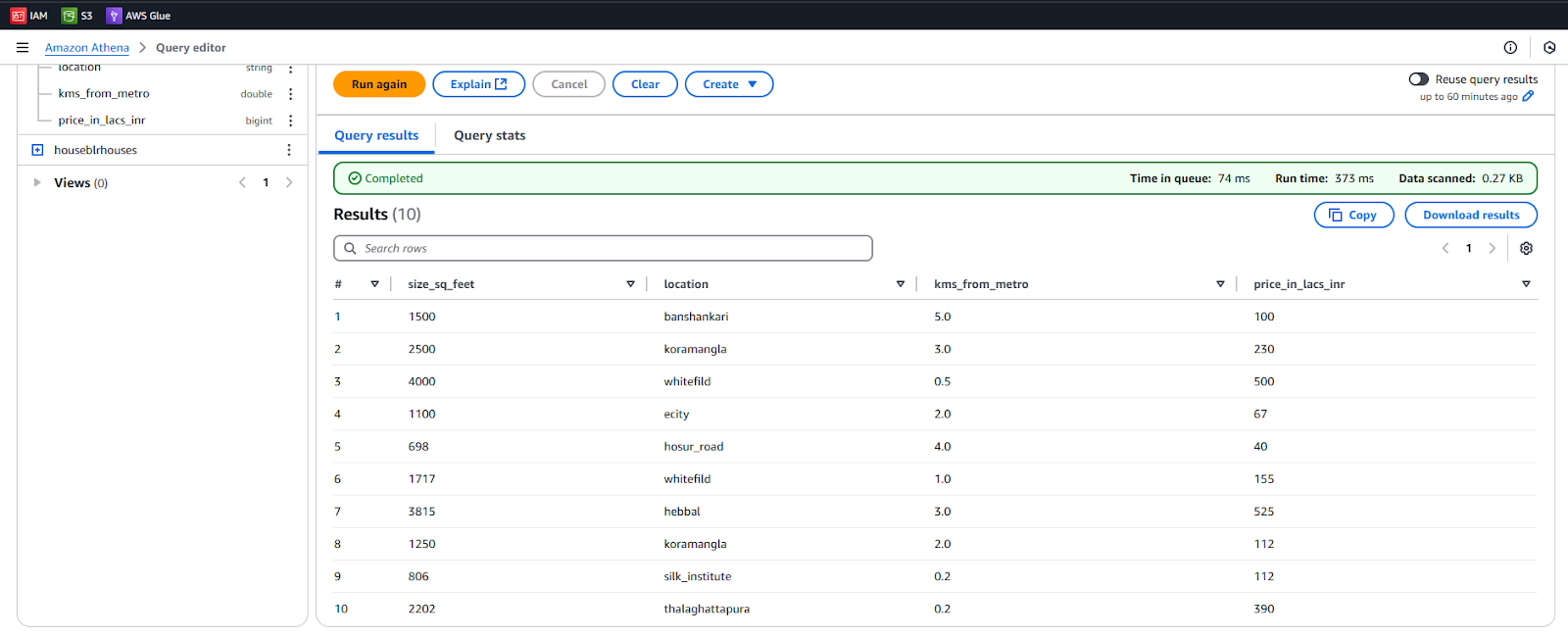
Let’s try one more query 🙂
Query: SELECT * FROM “AwsDataCatalog”.”houseprice”.”data_houses” where “kms_from_metro” < 1
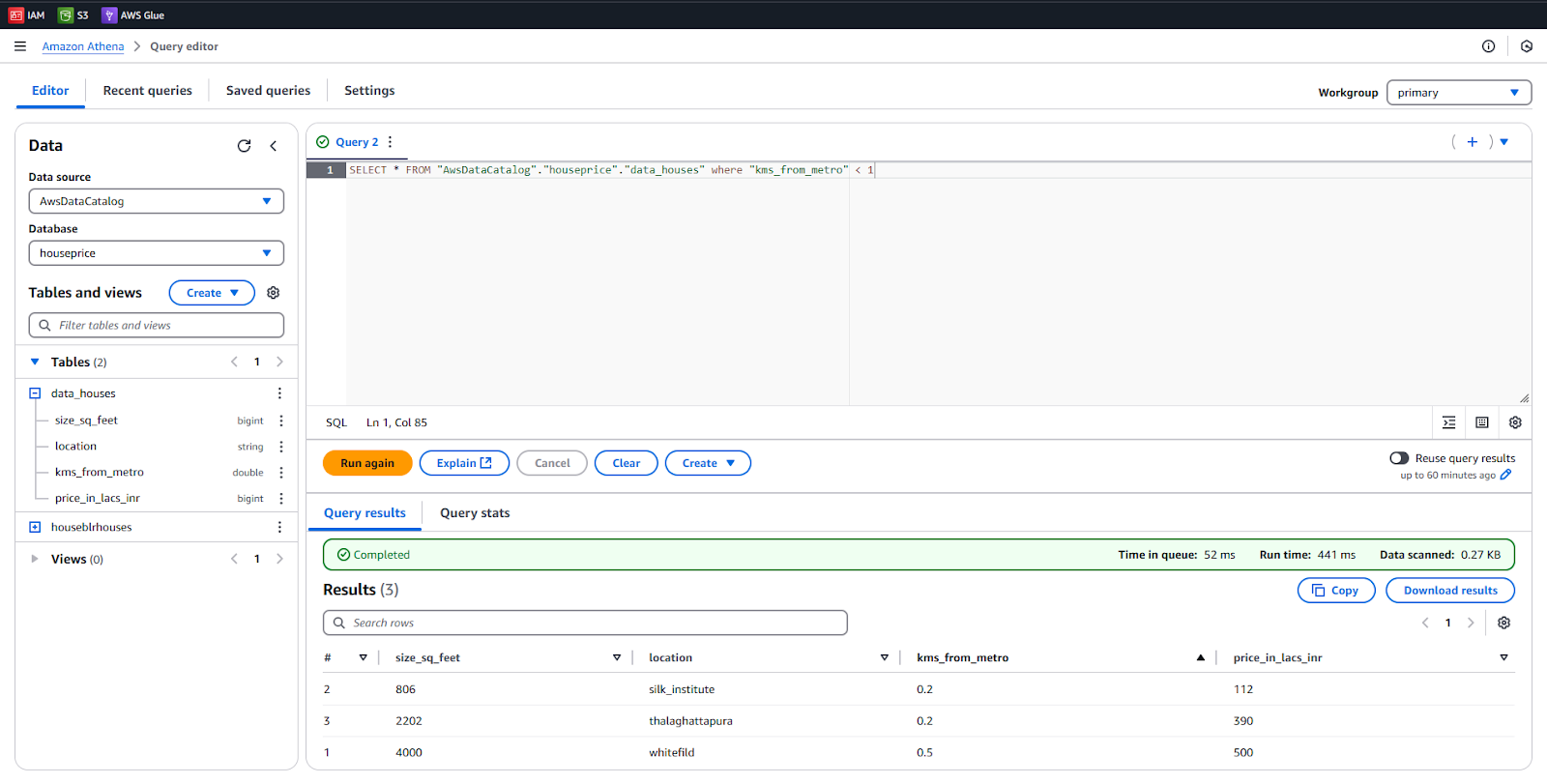
This is a simple example to view meaningful insights. Play with your Table and .CSV file to understand this process.
Experiment: Add a new data file and run the Crawler again to see the new entry in the above table.
We have specified the Crawler schedule on demand so we need to run Crawler again for a new entry. We can specify the desired frequency, such as every day at a particular time or every few hours. This will automate the process of discovering and cataloging data regularly. This ensures that your data catalog remains up-to-date with the latest changes in your datasets, such as new files, updated schemas, or modified data sources.
Next, we will see how to troubleshoot if we face some issues.
View the logs in CloudWatch for crawlers
Logs are always helping us to keep eye on what is happening?
- Search CloudWatch from AWS console
- Navigate to Log Groups
- Select Crawlers Log Group /aws-glue/crawlers
- Click on house_price Crawler to see the logs
In the following screenshot, We can view the Crawler Logs.
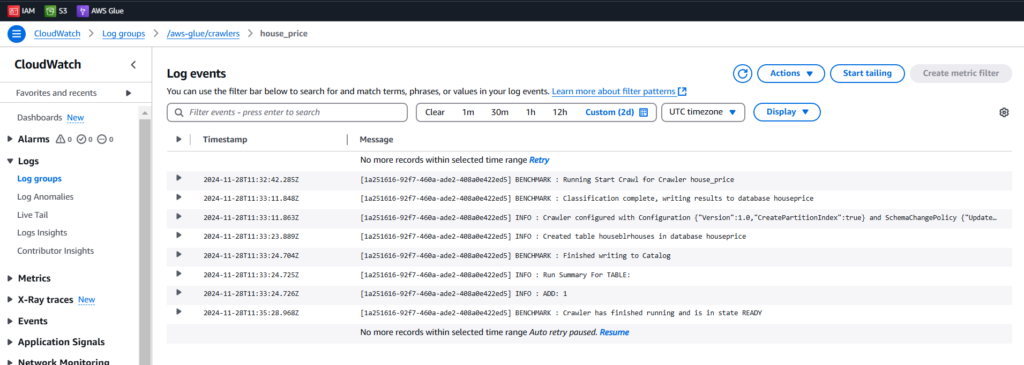
This would be useful if you face any issues in the Crawler.
Conclusion
AWS Glue and Athena revolutionize data transformation and querying. Glue automates ETL workflows and schema discovery, while Athena enables seamless SQL-based analysis of S3-stored data. Together, they simplify data preparation, reduce costs, and enhance scalability, empowering businesses to derive actionable insights efficiently. Stay connected for practical demos and use cases.
