In today’s data-driven world, the ability to process and analyze information in real-time has become a game-changer. AWS Kinesis is a powerful service designed to enable developers to collect, process, and analyze real-time, streaming data efficiently. In this blog, we will explore the features of AWS Kinesis and walk you through a hands-on demo showcasing its integration with DynamoDB and AWS Lambda for live data processing.

Let’s understand AWS kinesis in the following section.
What is AWS Kinesis?
AWS Kinesis is a real-time data streaming service that enables businesses to collect, process, and analyze data as it flows. It is designed to handle large-scale, continuous streams of data from various sources such as IoT sensors, application logs, and event trackers.
Primary Use Cases
- Real-Time Analytics: Monitor metrics such as website traffic or app usage instantly.
- Application Monitoring: Collect logs to identify bottlenecks or errors in real time.
- IoT Data Processing: Analyze data from connected devices as it is generated.
- Event Streaming: Enable applications to react to specific events instantly, such as fraud detection.
Components of AWS Kinesis
AWS Kinesis is composed of three main services, each tailored for specific data streaming needs:
- Kinesis Data Streams: For building custom real-time applications that process or analyze streaming data.
- Kinesis Data Analytics: Provides tools for running SQL queries on streaming data in real time to extract actionable insights.
- Kinesis Data Firehose: Automates the process of loading streaming data into AWS destinations like S3, Redshift, or Elasticsearch.
We are focusing on Kinesis data stream in this post.
What is a Data Stream?
A Kinesis Data Stream is a service that allows real-time streaming of data between producers (data sources) and consumers (data processing applications). It enables seamless ingestion of high-throughput data while ensuring durability and scalability.
Key Features and Benefits of Kinesis Data Streams
- Scalability: Automatically adjusts to handle gigabytes of data per second.
- Low Latency: Ensures real-time data processing with minimal delays.
- Data Durability: Stores data across multiple Availability Zones for fault tolerance.
- Shard-Based Architecture: Allows fine-grained control over data throughput and scaling.
- Integration with AWS Ecosystem: Works seamlessly with Lambda, DynamoDB, S3, and more.
How Kinesis Data Streams Work?
- Producers: Data sources send records to a Kinesis stream, such as IoT devices or application logs.
- Stream: Data is divided into shards, which determine the throughput of the stream. Each shard processes and retains data for up to 24 hours (or longer with extended retention).
- Consumers: Applications or services like AWS Lambda retrieve and process data from the stream in real time.
Why Choose AWS Kinesis for Real-Time Data Streaming?
- Cost Efficiency: Pay for what you use with flexible pricing based on data throughput.
- Ease of Use: Simplified setup and integration with other AWS services.
- Real-Time Decision Making: Enables immediate actions based on streaming data.
AWS Kinesis is often compared to Apache Kafka, as both are powerful tools for handling real-time streaming data. While they serve similar purposes in data ingestion and processing, Kinesis is a fully managed service provided by AWS, making it easier to integrate with other AWS services, while Apache Kafka offers more flexibility for self-managed setups.
We will see the implementation of streaming and processing data in the next section.
Demo: Hands-On with Kinesis Data Streams
We’ll create a real-time pipeline using AWS Kinesis, DynamoDB, and AWS Lambda for data analytics. we will generate random data through Python script and send real-time data to the kinesis data stream.
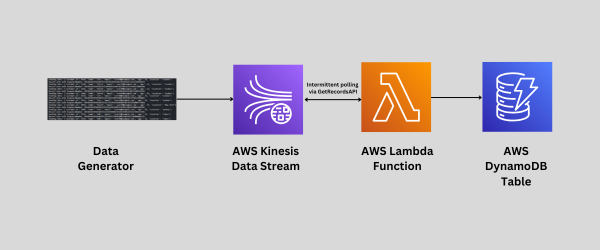
Follow the steps to achieve real-time data analytics as shown in the above figure.
- Create a Kinesis Data Stream
- Data Generation
- Create DynamoDB Table to Perform Some Useful Analytics
- Create a Role for Lambda Function
- Lambda Function to Get Data from Stream to Table
- (optional step): Logs in CloudWatch
- Query on Table Data Using Primary Key
Let’s start the implementation with the very first step.
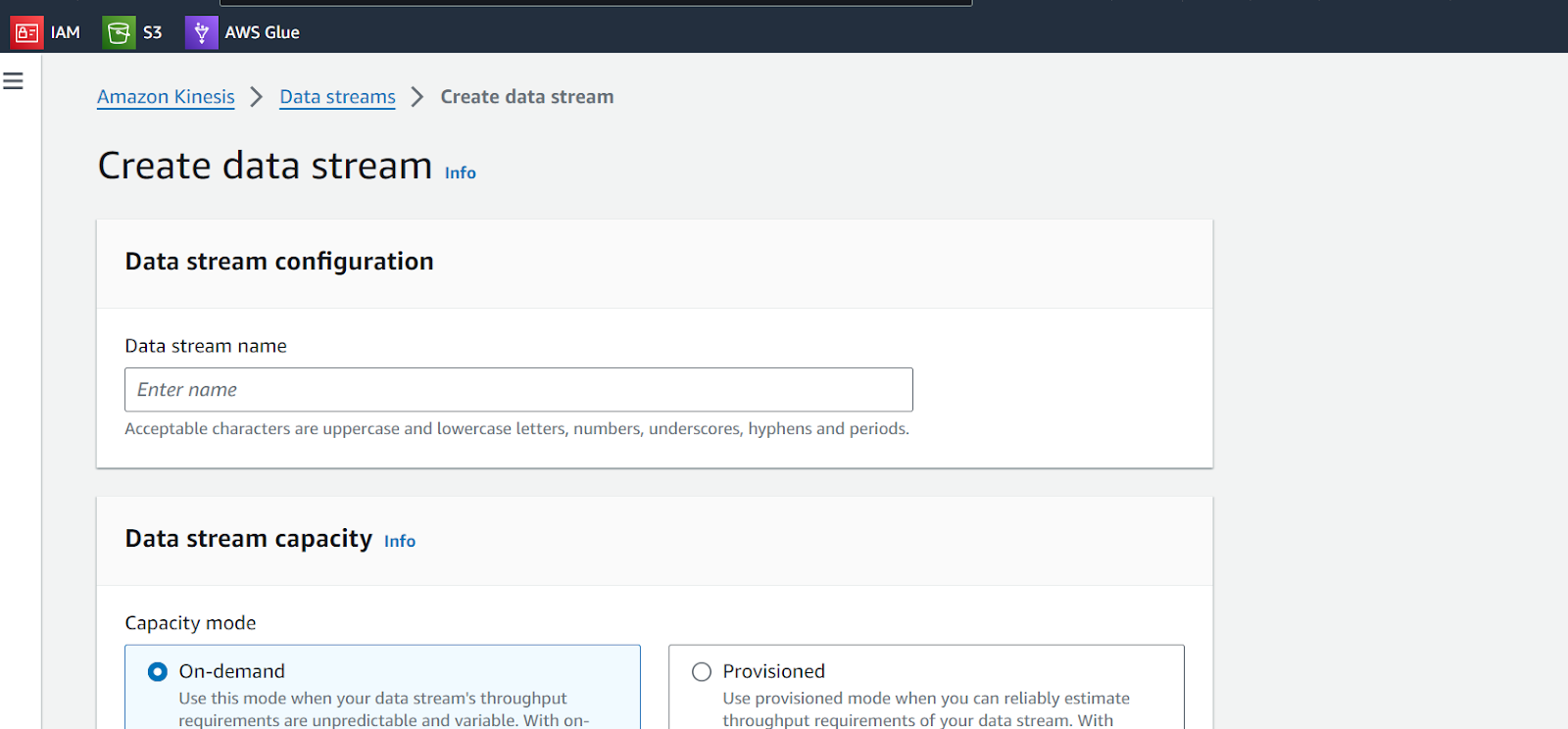
Step 1 : Create a Kinesis Data Stream
This Data Stream is used to send real-time data to the DynamoDB for analysis.
- Search Kinesis on AWS console
- Select Data streams from the menu
- Click on Create data stream option and configure your data stream
- Data stream name: Provide a name to your stream (CustomerStream)
- Data stream capacity: Select provisioned as a capacity mode
- Number of shards: 1 (Enough for this example)
- Keep other parameters as a default
- Create data stream
It will take a few seconds to create a Data stream with active status.
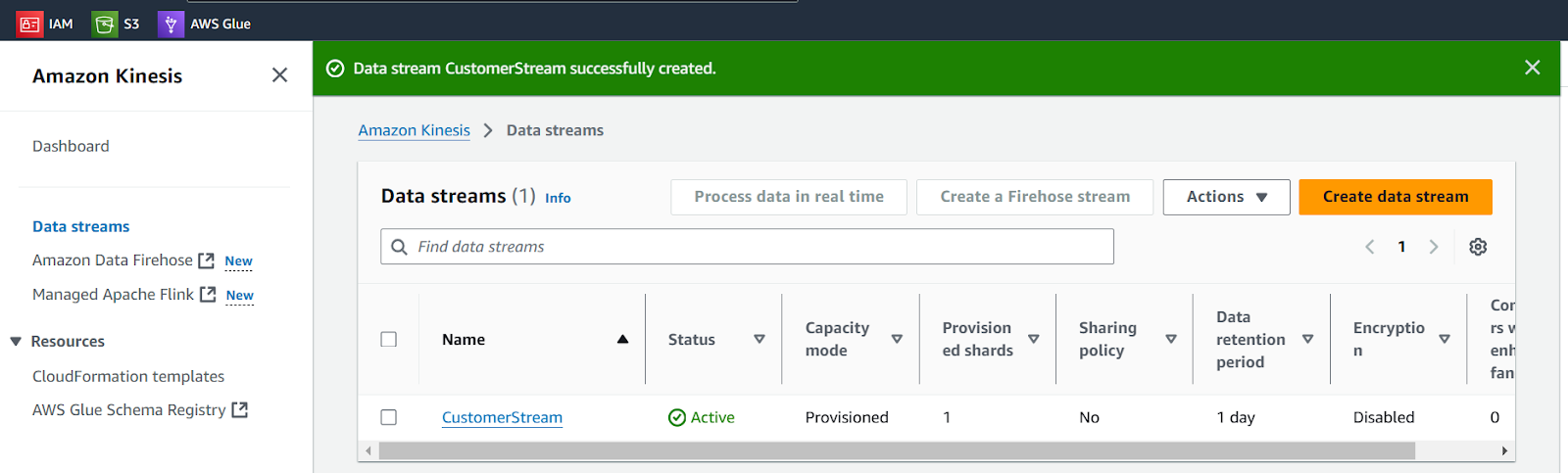
Now, we are ready for data generation as our stream is ready to accept data.
Step 2: Data Generation
We’ll generate data using a Python script.
- Open CloudShell from AWS console
- Add a script using nano
- Cutomise this script
- Configure your Kinesis stream
- stream_name: Make sure to replace your-kinesis-stream-name with the name of your own Kinesis stream.
- region_name: Update your-region-name with your AWS region
- Configure your Kinesis stream
- Once you have updated these placeholders with your specific stream name and region, the script will work for your AWS Kinesis setup.
- Cutomise this script
- Run the Python file from CloudShell
python3 data_generator.py
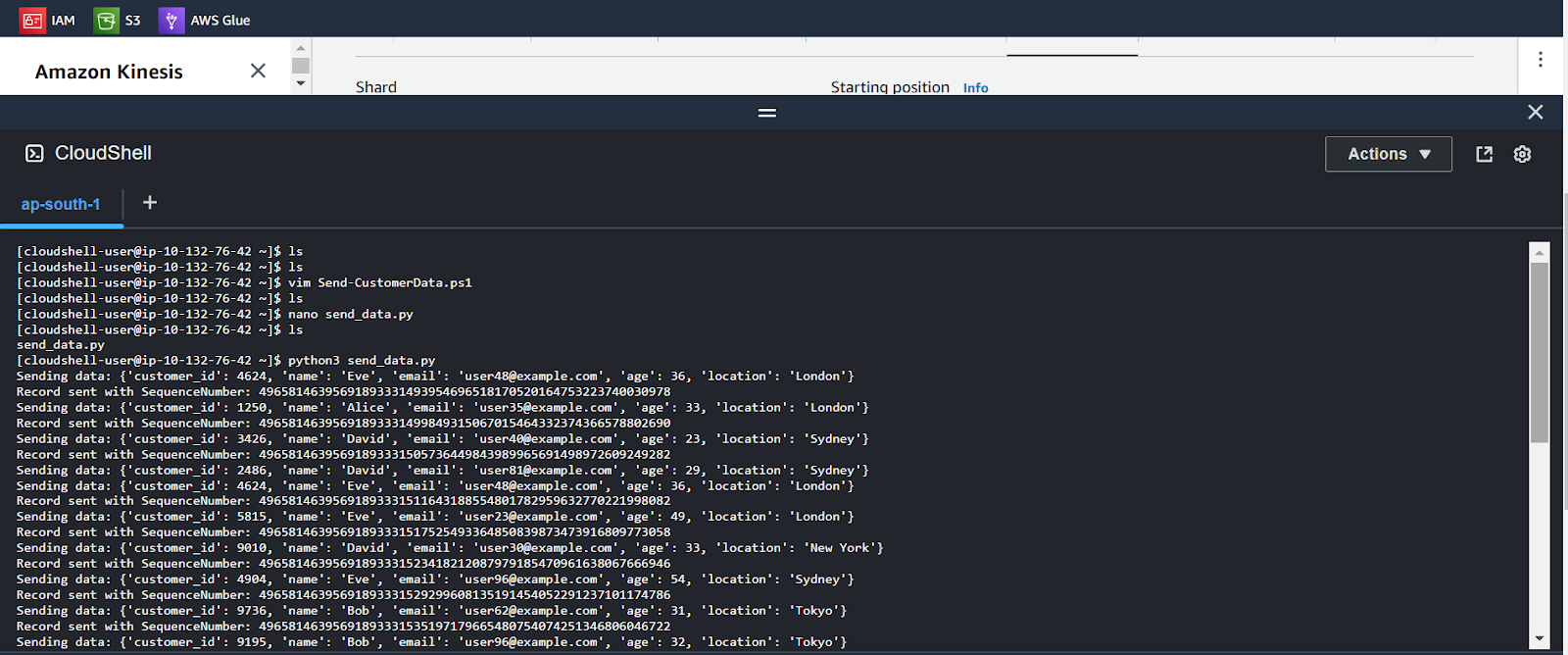
This Python script will send random data continuously to the data stream. You can verify data in your Kinesis data stream that is created in step 1. Next, we will create a database to store this data.
Step 3: Create DynamoDB Table to Perform Some Useful Analytics
Search DynamoDB from AWS console and select Tables from the menu.
- Select Create table option and configure your table
- Table name: Provide appropriate name (customer-data)
- Partition key (primary key): Use schema that hold unique value(customer_id)
- Sort key as default
- Table settings: Keep default settings
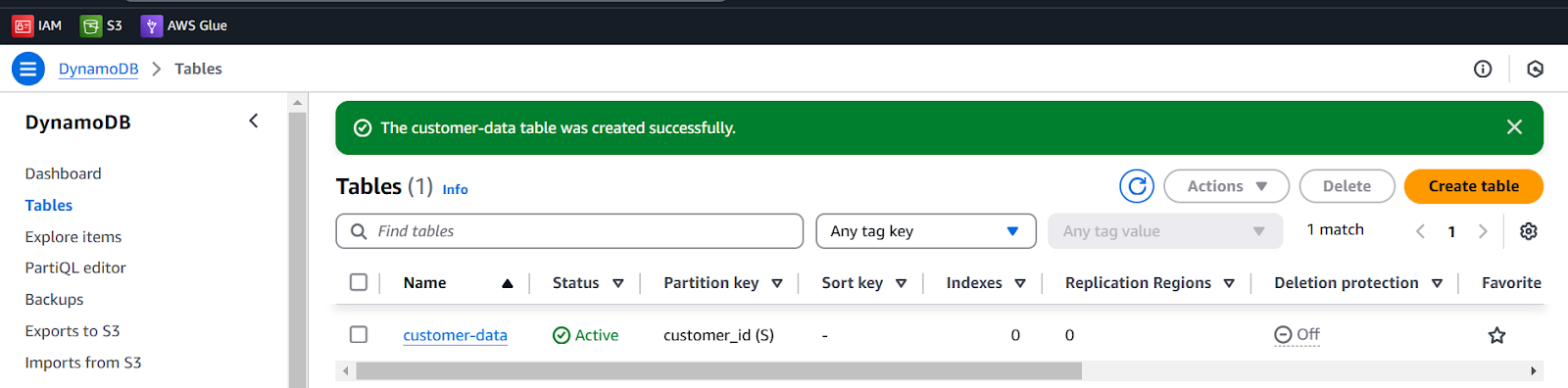
- Create table
It will take a few seconds to create an empty table with active status. We don’t have items. you can verify it by selecting Explore items from the menu or by selecting table (customer-data).
Now, we have all resources ready so we will bind them with a Lambda function. First, we will create an IAM role for Lambda function.
Step 4: Create a Role for Lambda Function
A Lambda function should be able to access all the resources. Search IAM role from the AWS console and create a new role.
- Create a role
- Provide a name to the role (AWSLamdaFullAccess)
- Add permissions like
- AmazonDynemodbFullAccess
- AmazonKinesisFullAccess
- AWSLambda_FullAccess
- AWSLambdaBasicExecutionRole
- View your IAM Role
Added a policy AWSLambdaBasicExecutionRole to produce log to CloudWatch (Enable logging through IAM role)
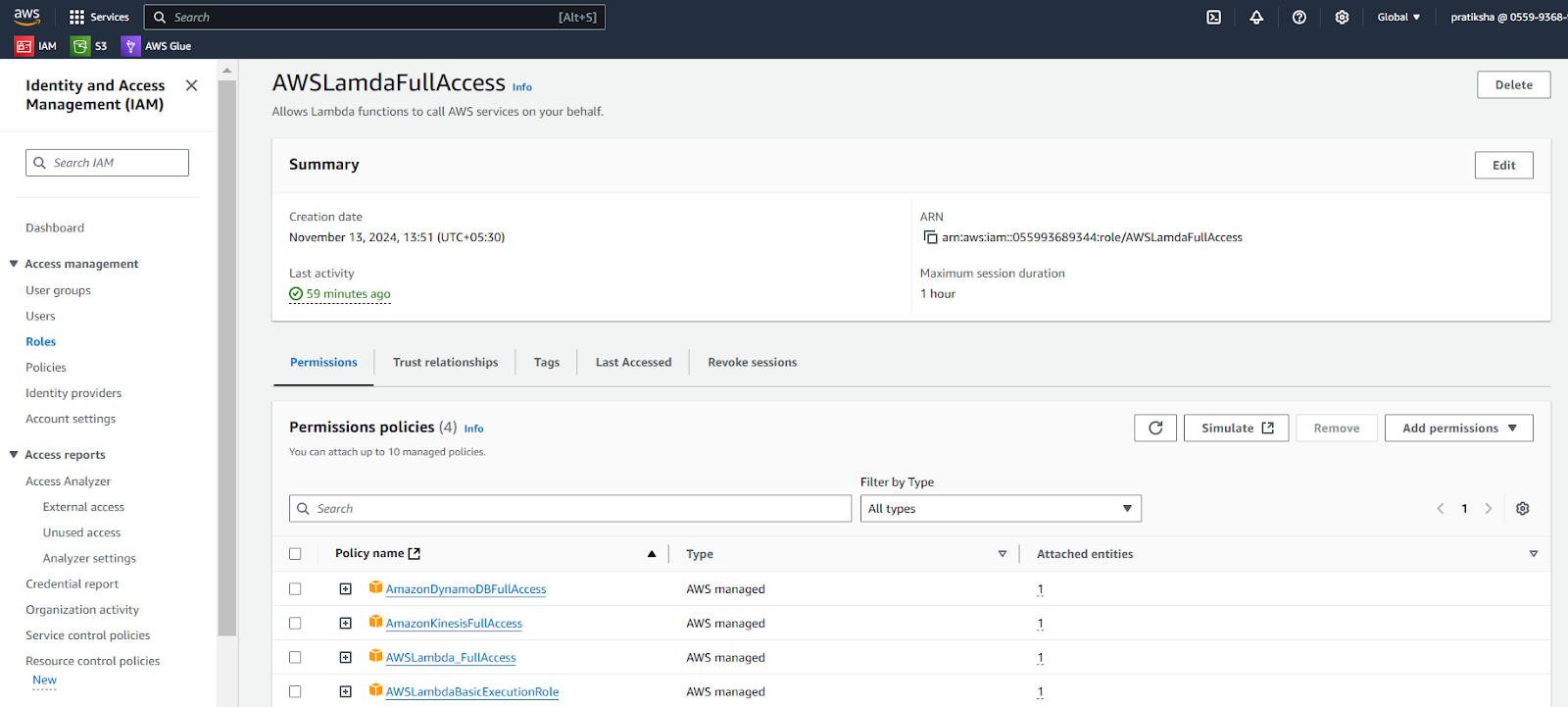
With using the above policies (IAM Role) Lambda Function is ready to integrate all resources.
Step 5: Lambda Function to Get Data from Data Stream to Table
Search Lambda from AWS console and select Function from the menu to create new one.
- Create function
- Select From scratch option
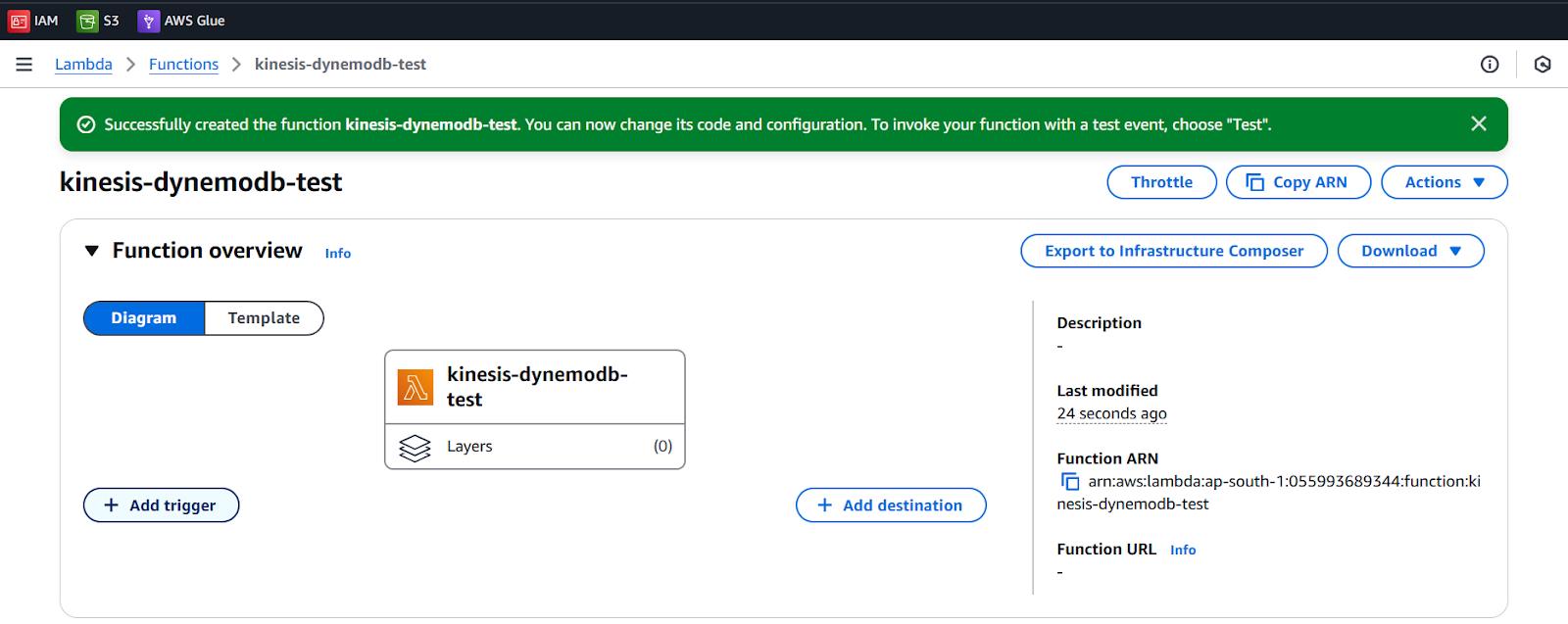
- Function name: Any name of your choice (kinesis-dynemodb-test)
- Select runtime: python 3.11
- Change default execution role
- Select Existing role: AWSLamdaFullAccess (we created in the previous step)
- Keep Advanced settings as default
- Create a function
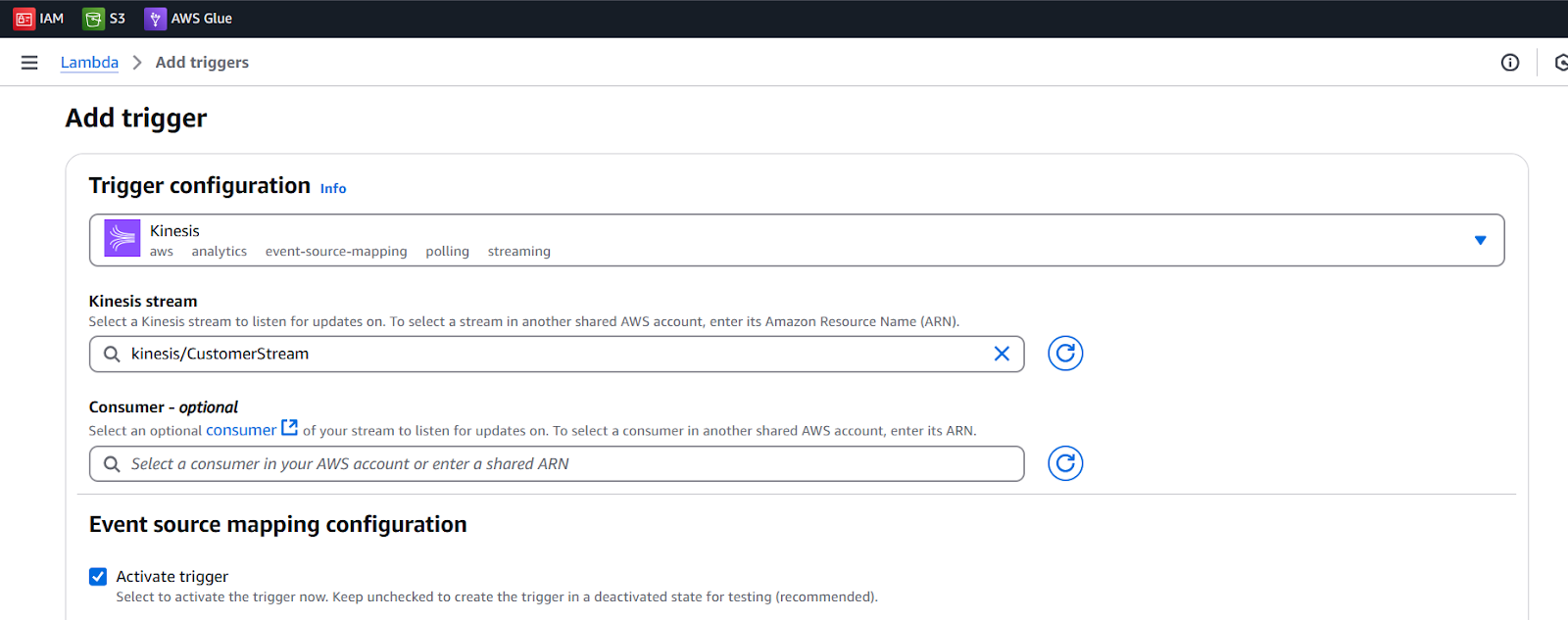
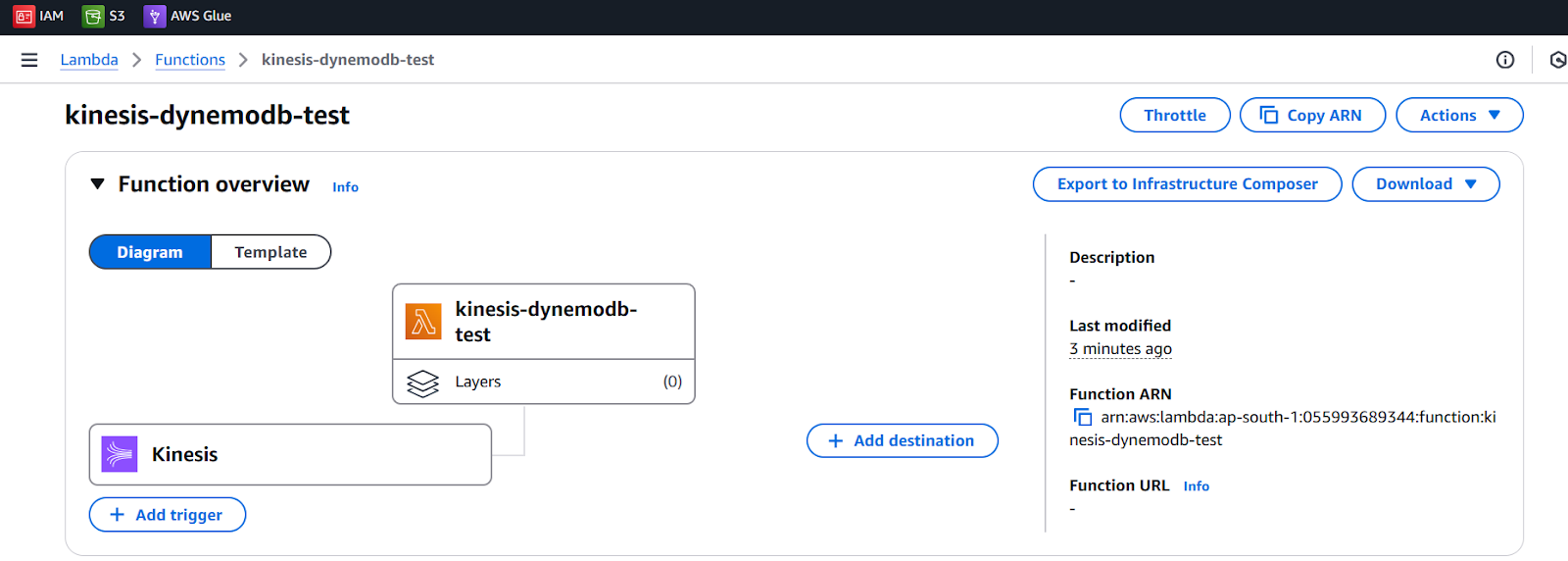
- Now click on Add trigger from the Function overview Diagram
- Select kinesis in trigger configuration
- Kinesis stream will be added automatically like kinesis/Customerstream
- Activate trigger
- Write a lambda function code in Python
- Deploy this function
Our Lambda function is ready to trigger when new data comes in Kinesis data stream.
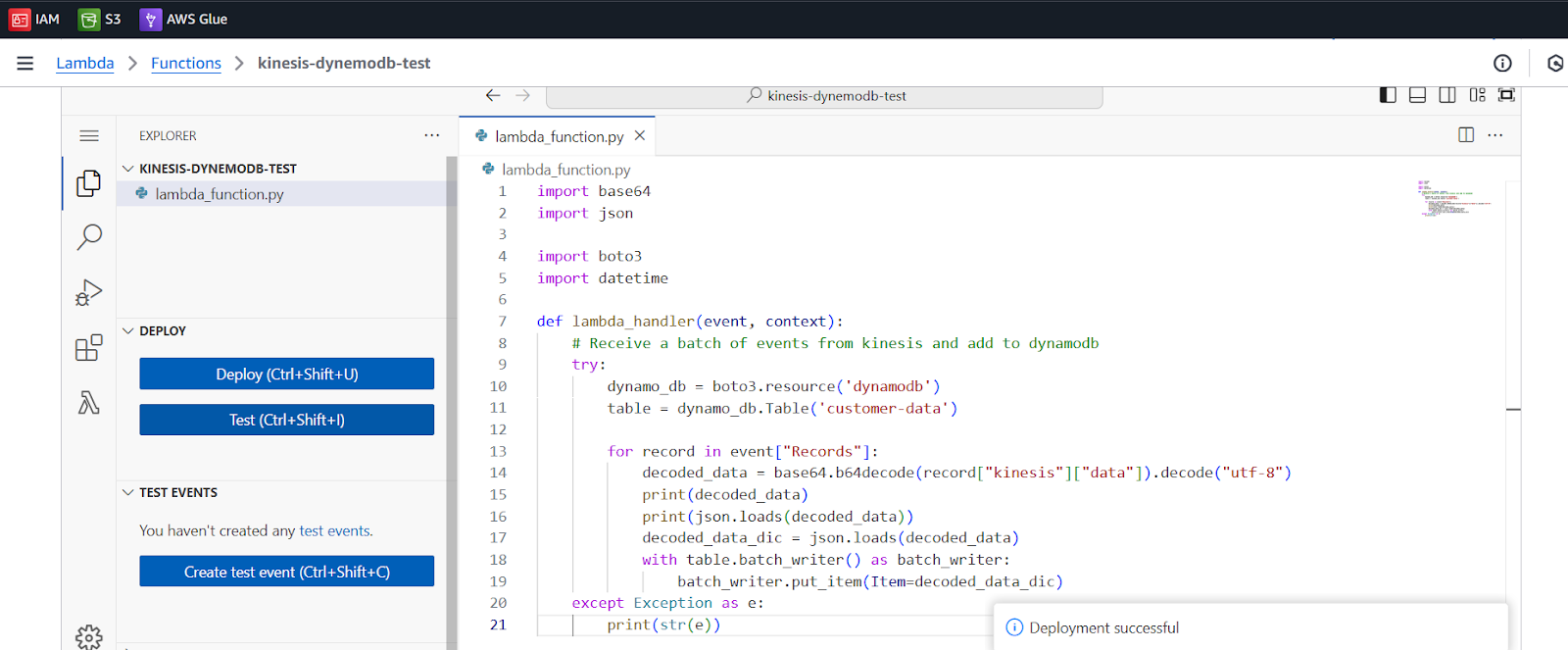
Now, send data from CloudShell as done in Data Generation step and see live data in Dynamodb table records because of the Kinesis trigger.
- Run the script again,
python3 data_generator.py
We can see the records in the DynamoDB Table by selecting Explore items.
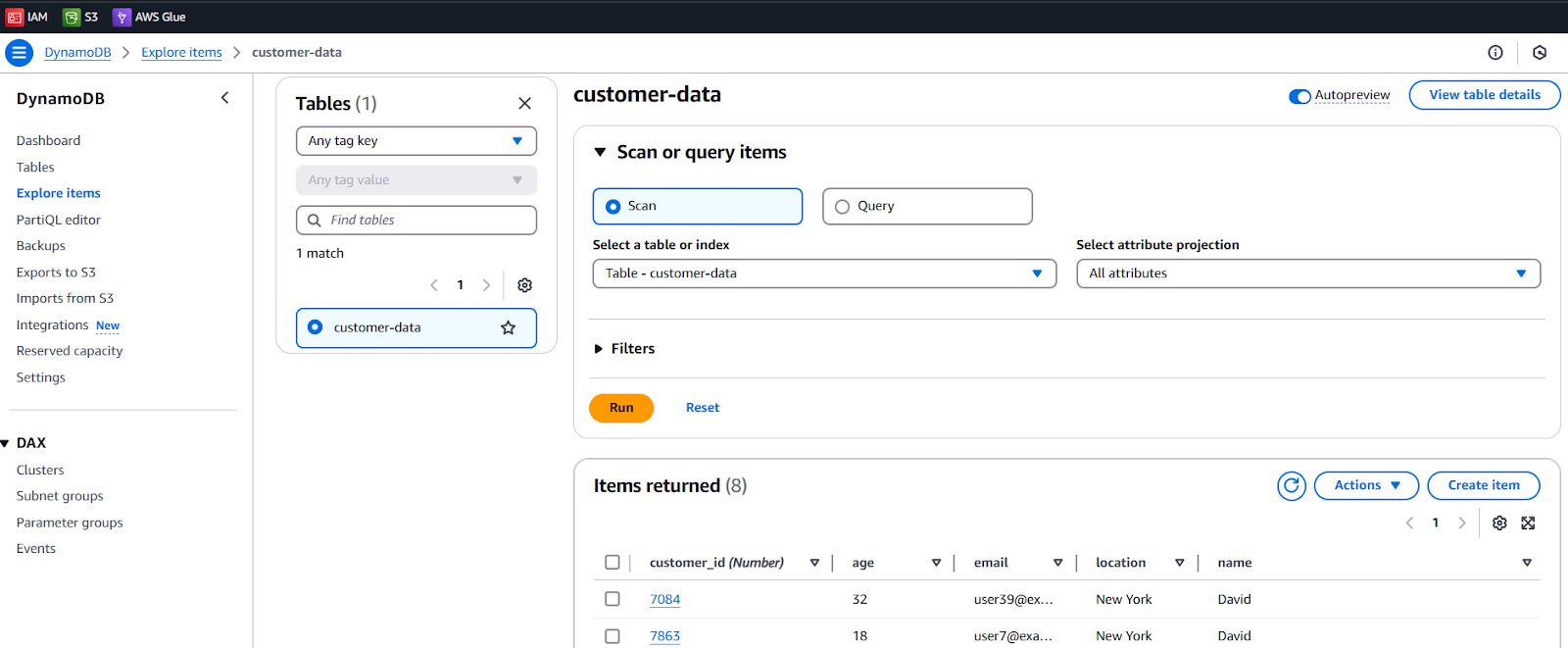
- Refresh the Items returned to get live data.
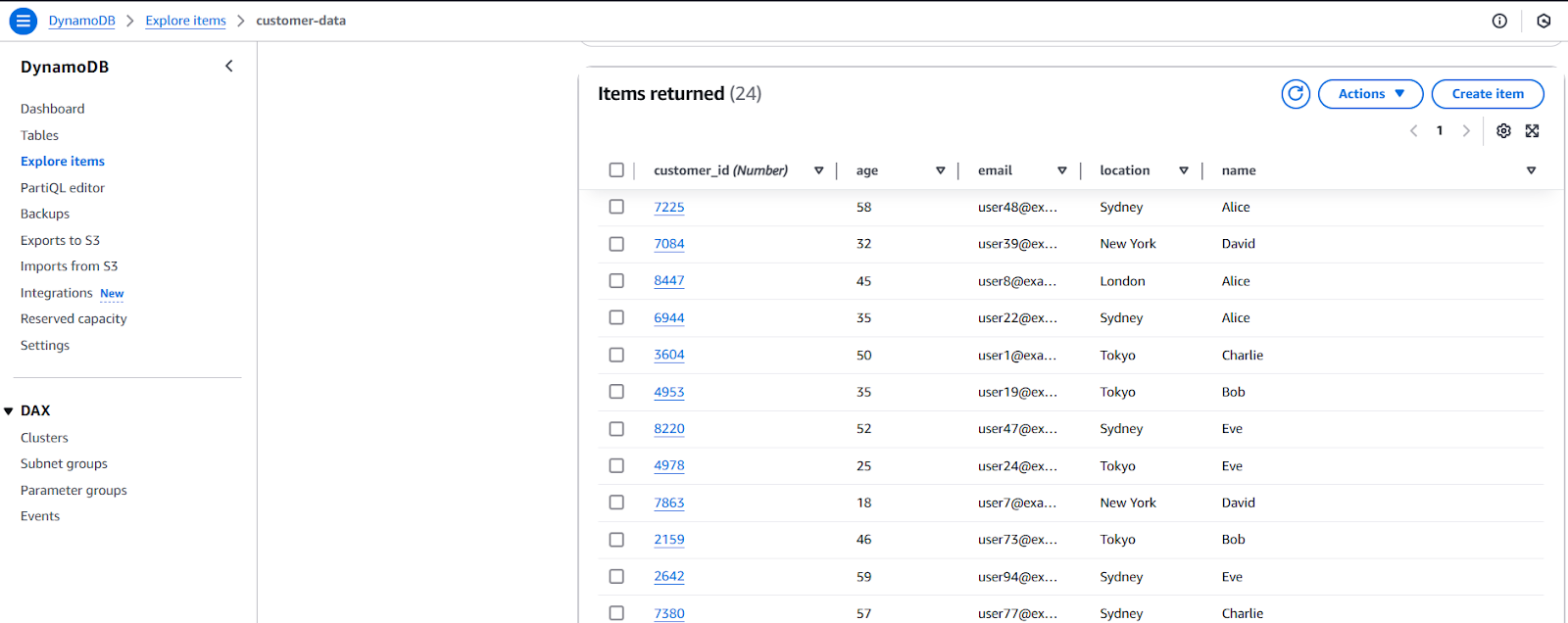
We can easily do the analysis from the table records. next step is optional but important for troubleshooting.
Step 6(optional): Logs in CloudWatch
View the logs of Lambda function,
- Search CloudWatch from the console
- select Log groups from Logs menu
- Click on your lambda function logs (/aws/lambda/kinesis-dynemodb-test) to understand the issue or the process.
- See the Log events
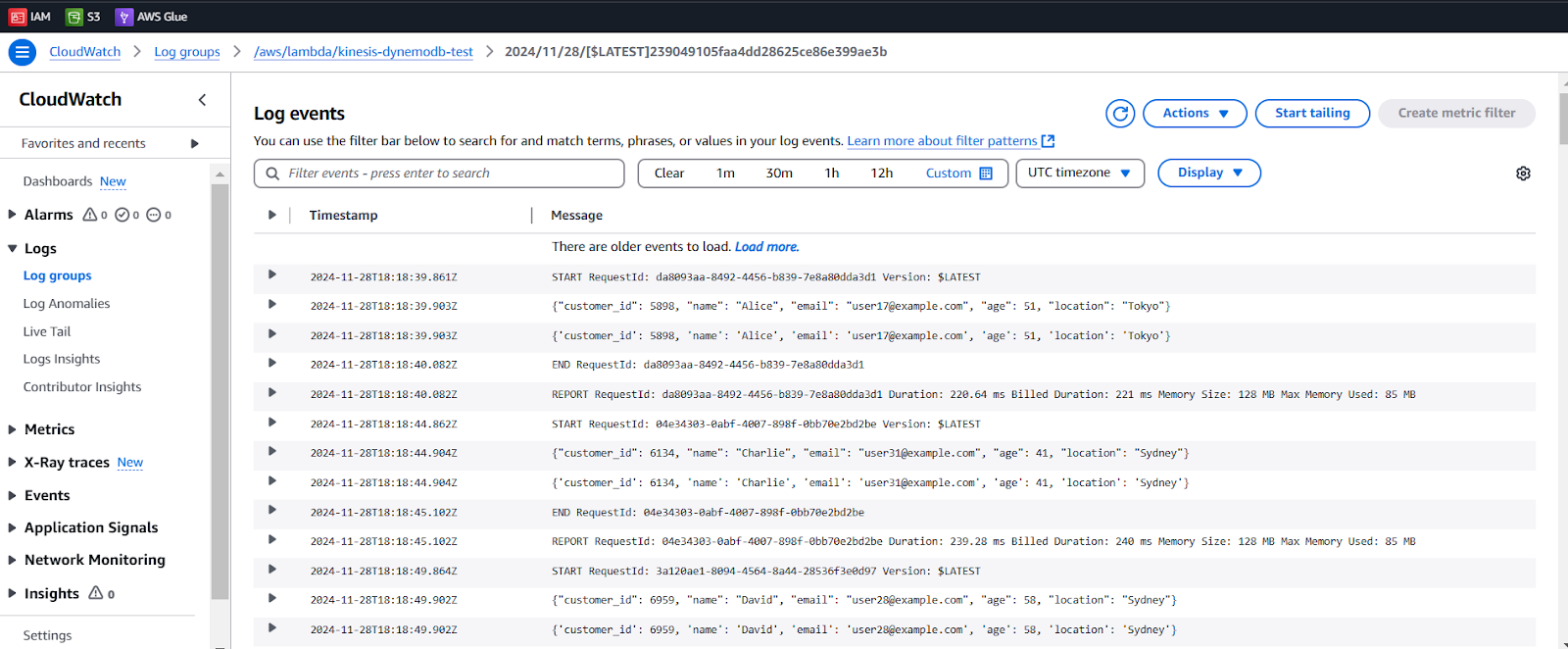
Here we can see the whole process done in Lambda Function. Let’s do the final step which is query on table data.
Step 7: Query on Table Data Using Primary Key
Let’s analyze the table data.
- Explore items in the DynamoDB
- Select your (customer-data) table
- Query a particular record using primary key (customer_id)
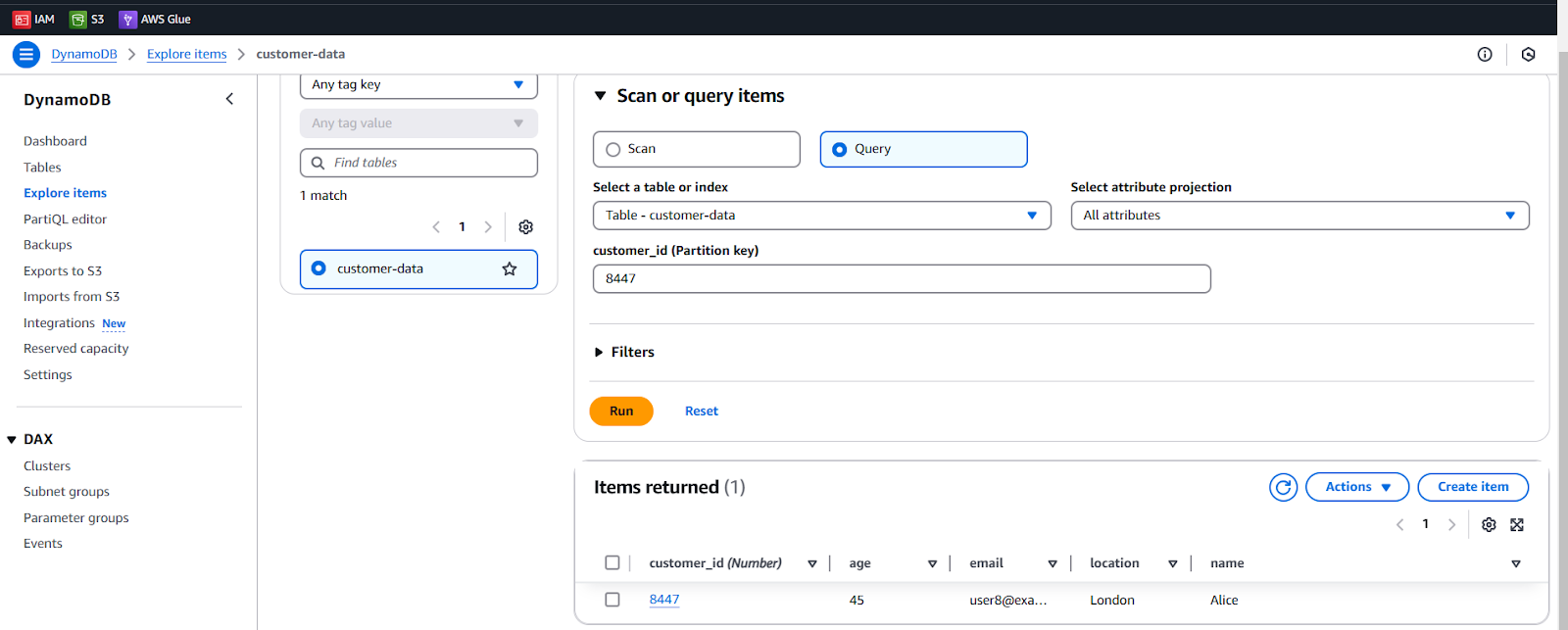
We can download the result to CSV from Actions. Play with other options in Explore items.
Conclusion
AWS Kinesis empowers businesses to harness the power of real-time data streaming, offering tools for ingesting, processing, and analyzing high-throughput data. Whether it’s analyzing clickstream data, processing IoT signals, or enabling predictive analytics, Kinesis provides the scalability and reliability needed for modern, data-driven enterprises. Stay tuned as we dive deeper into the implementation of Kinesis Data Streams and its integration with AWS services in our upcoming posts!
