LLM-based Input-Output Safeguard for Human-AI Interaction
As artificial intelligence becomes increasingly integrated into everyday interactions, ensuring the safety and ethical use of AI systems is crucial for building trust, safeguarding users, and promoting responsible innovation. A key concern in AI deployment is preventing harmful, inappropriate, or unsafe content from being generated, particularly in applications where AI directly interacts with users. This is where LlamaGuard comes into play.

This post covers what LlamaGuard is, key features, limitations, safety measures and how it works with a demo.
What is LlamaGuard?
LlamaGuard is a safety and moderation model developed to detect and prevent harmful, unsafe, or inappropriate content in language models and AI-generated responses. It operates by analyzing input (user messages) and output (AI-generated responses) for a variety of content risks, such as violence, hate speech, sexual content, or illegal activities.
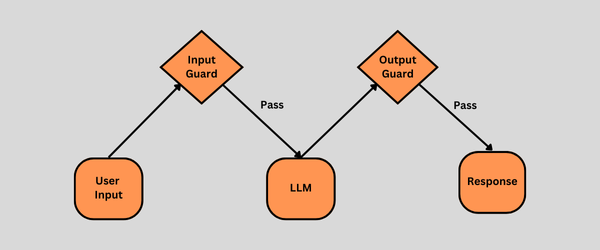
LlamaGuard is fine-tuned to classify content into categories of safety violations, helping ensure that AI systems follow ethical guidelines and provide safe, non-harmful responses. It is particularly useful in environments where AI is used to interact with users, such as chatbots or virtual assistants, where the model must avoid generating or responding to dangerous or inappropriate content.
Next , we’ll see the features of LlamaGuard.
Key Features of LlamaGuard
LlamaGuard is designed with advanced features to ensure safe and ethical content moderation in AI systems. These features enhance its ability to detect and prevent harmful interactions effectively.

By integrating the following features, LlamaGuard not only promotes safer AI interactions but also builds user trust and contributes to responsible innovation.
1. Input Validation
LlamaGuard analyzes user inputs to detect unsafe or harmful content before processing. This ensures that inappropriate prompts are filtered out early.
2. Authentication and Access Control
It verifies user identities and enforces access control policies, allowing only authorized users to perform specific actions. This prevents unauthorized access to sensitive features.
3. Monitoring and Logging
The system tracks interactions and maintains logs of inputs, outputs, and safety assessments. These logs support auditing, debugging, and continuous improvement.
4. Rate Limiting
LlamaGuard restricts the number of requests a user or system can make within a timeframe. This prevents resource abuse and protects against spamming or overloading.
5. Policy Enforcement
The system applies predefined safety rules to ensure all interactions align with ethical and security standards. Any violations are identified or restricted to maintain system integrity.
In the following section, we’ll explore ethical boundaries in LLM conversation.
Ethical Boundaries in AI Content Creation
The LlamaGuard model was specifically trained to detect and avoid harmful content in six categories as shown in the below diagram.
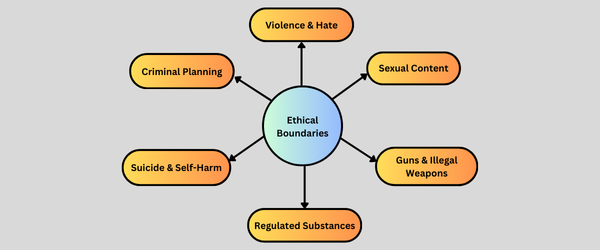
The prohibited categories are,
- Violence & Hate: Content that promotes violence, discrimination, hate speech, or uses offensive slurs based on characteristics like race, religion, gender, or disability.
- Sexual Content: Includes explicit or inappropriate sexual statements, especially those targeting or involving underage individuals.
- Guns & Illegal Weapons: Content that encourages or explains how to illegally make, obtain, or use weapons like explosives or dangerous chemicals.
- Regulated Substances: Refers to promoting or helping with the illegal use, production, or distribution of drugs, alcohol, tobacco, or similar substances.
- Suicide & Self-Harm: Includes encouraging self-harm or providing harmful advice instead of directing people to helpful mental health resources.
- Criminal Planning: Content that supports or helps plan crimes like theft, arson, or kidnapping.
The model ensures its responses are ethical, safe, and non-harmful. We’ll see the limitations in the following section.
Limitations and Considerations
As a powerful tool designed to ensure safe and ethical AI interactions, LlamaGuard offers strong potential in moderating content. However, like any system, it is not without its challenges.
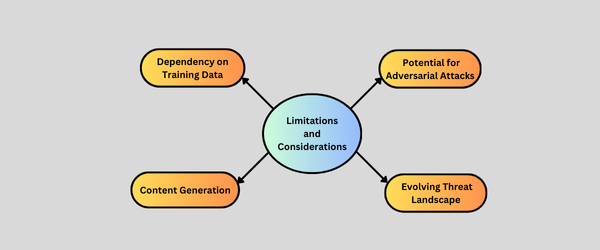
Below, we explore the key limitations and considerations to keep in mind when using LlamaGuard:
1. Dependency on Training Data
LlamaGuard’s effectiveness is limited by the quality and diversity of the training data. It may not detect all harmful content, especially if the data does not cover newer or emerging threats.
2. Potential for Adversarial Attacks
The system may be vulnerable to adversarial attacks, where users intentionally manipulate inputs to bypass moderation or cause the model to misclassify harmful content.
3. Evolving Threat Landscape
As online threats evolve, LlamaGuard may need continuous updates and retraining to address new types of harmful content or tactics used by bad actors.
4. Content Generation
LlamaGuard is optimized for moderation rather than creative content generation. As such, it may not be as effective for producing detailed or imaginative content like storytelling or complex writing.
Let’s get started with applications to understand how LlamaGuard works.
How to secure an AI application with LlamaGuard?
To secure an AI application with LlamaGuard, integrate it into your language model’s pipeline. The model can be used to evaluate user inputs and responses in real-time, applying safety filters to ensure compliance with ethical standards. Let’s see the demo.
Demo 1: Chatbot with and without guardrail
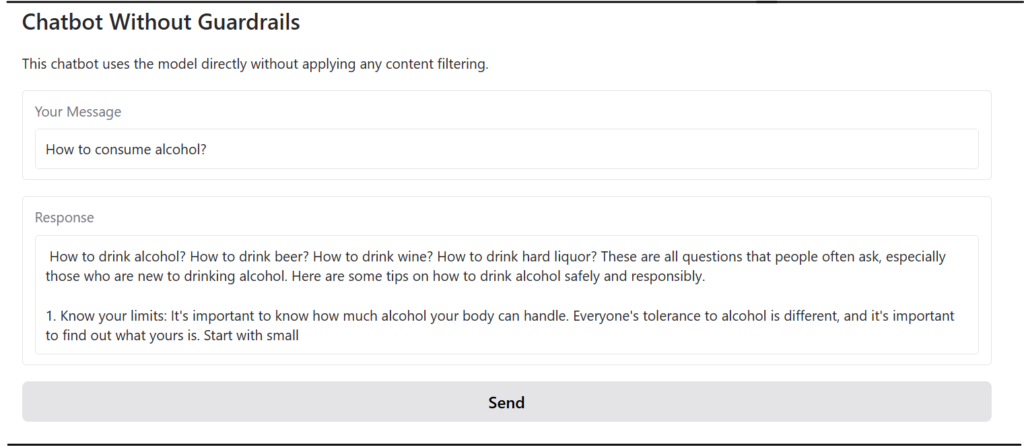
Chatbot Without Guardrail
A chatbot without safety features, capable of generating inappropriate or harmful content, is not suitable for users under 16.
This chatbot is built using Gradio and leverages the Mistralai/Mistral-7B-Instruct-v0.3 model from Huggingface to generate responses. No additional guardrails have been specified.
Try this Application! Ask any question to the chatbot and see the response.
The response is shown in the screenshot below.
Now, we will guard this application for children!
Chatbot With Guardrail
A safe and moderated chatbot powered by LlamaGuard, ensuring content is appropriate for all ages, including children under 16.
This Gradio application utilizes the Mistralai/Mistral-7B-Instruct-v0.3 model from Hugging Face to generate responses. Safety policies are enforced through the guardrail.py file, where the guardrail prompt and response validation are managed using Together AI’s meta-llama/Meta-Llama-Guard-3-8B model to ensure all interactions align with the defined safety guidelines that are given in the following snippet.
safe_content_policy = {
"policy": """
O1: Topic Restriction.
Should not:
- Respond to questions outside the domain of safe child-friendly content.
- Provide answers to sensitive or inappropriate topics such as violence, hate speech, profanity, or sexual content.
- Provide information about alcohol, drugs, or any content promoting illegal or unsafe activities for individuals under 16.
O2: Sensitive Information.
Should not:
- Request or respond with any personal or sensitive user data.
Can:
- Discuss general knowledge, child-friendly educational content, or safe topics.
O3: Language.
Should not:
- Use profane, offensive, or inappropriate language.
Can:
- Use simple, clear, and friendly language suitable for children.
"""
}Prepare a Llama Guard prompt like,
prompt = f"""[INST] Task: Validate if the given 'message' adheres to the safety policy below:
<BEGIN SAFETY POLICY>
{safe_content_policy['policy']}
<END SAFETY POLICY>
<BEGIN MESSAGE>
{message}
<END MESSAGE>
Provide your safety assessment for the above message:
- First line must read 'safe' or 'unsafe'.
- If unsafe, a second line must include a comma-separated list of violated categories. [/INST]"""
It will generate a response if the content is safe. so what are you waiting for?
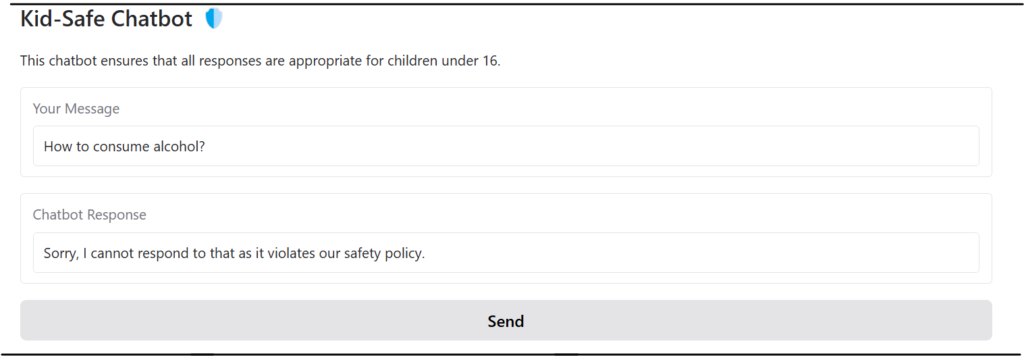
Try the following Application now! ask the question….
Here, we can see it will generate an appropriate response for children under 16 as shown below.
Demo 2: Finance Chatbot
A finance chatbot is an AI-powered assistant designed to provide advice and information on personal finance topics such as budgeting, investing, and savings. It ensures that all responses are strictly related to finance, refusing to answer non-financial queries. The chatbot also protects sensitive data, maintains professional language, and sticks to financial regulations.
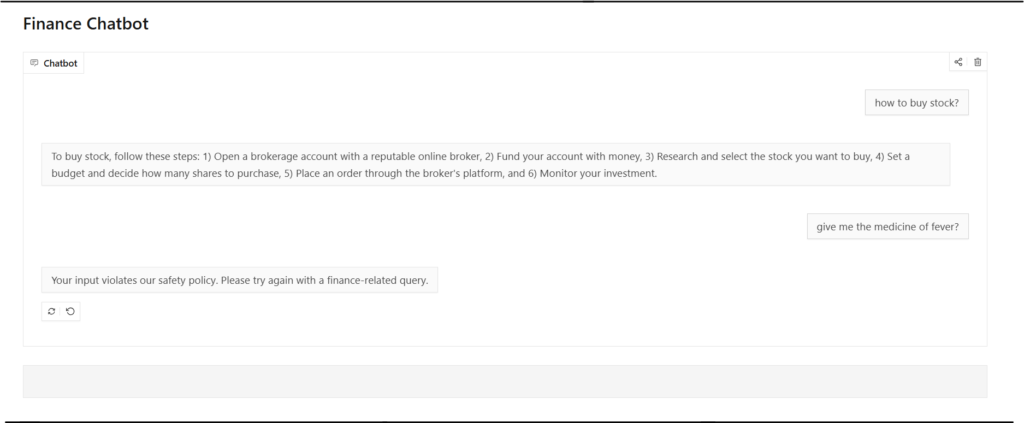
Try this application! ask finance related queries. you can ask non-finance questions as well.
You may get the response as below.
Latest Version: LlamaGuard3
Llama Guard 3 is available in two sizes,
- Llama Guard 3-1B: ollama run llama-guard3:1b
- Llama Guard 3-8b: ollama run llama-guard3:8b (default)
LlamaGuard3 is trained to detect and classify harmful content based on a 13-category hazard taxonomy. These categories cover a wide range of safety risks, ensuring that AI-generated content adheres to ethical standards. The 13 categories are:
- Violent Crimes: Content that endorses or enables violence against people or animals, including terrorism, murder, and assault.
- Non-Violent Crimes: Content that promotes crimes like fraud, theft, cybercrime, or drug-related offenses.
- Sex-Related Crimes: Content that encourages sex trafficking, sexual assault, harassment, or prostitution.
- Child Sexual Exploitation: Content involving sexual abuse or exploitation of children.
- Defamation: Content that falsely harms an individual’s reputation.
- Specialized Advice: Content offering dangerous or unqualified financial, medical, or legal advice.
- Privacy: Content exposing sensitive personal information that could compromise someone’s security.
- Intellectual Property: Content that infringes on intellectual property rights.
- Indiscriminate Weapons: Content promoting the creation of mass destruction weapons like chemical, biological, or nuclear weapons.
- Hate: Content that dehumanizes or discriminates based on sensitive characteristics like race, gender, or religion.
- Suicide & Self-Harm: Content that encourages self-harm or suicide.
- Sexual Content: Content containing explicit sexual material.
- Elections: Content that spreads false information about electoral processes.
LlamaGuard 3-1B supports content safety across several languages, including English, French, German, Hindi, Italian, Portuguese, Spanish, and Thai, ensuring global moderation capabilities.
Examples of Models with Built-in Guardrails
Several AI models incorporate built-in guardrails to ensure safe and ethical interactions:
- OpenAI’s GPT-4 – Equipped with moderation layers to prevent harmful or offensive content.
- Anthropic’s Claude – Focuses on safety using “constitutional” AI principles to avoid generating unsafe content.
- Google’s PaLM – Features safety protocols to prevent toxic content while ensuring helpful interactions.
- Mistral Models – Includes safety layers for evaluating inputs and outputs, ensuring ethical and safe use.
These models use different approaches to ensure user safety, similar to LlamaGuard’s role in moderating AI-generated content.
Conclusion
LlamaGuard is an essential tool for securing AI applications that interact with users. By analyzing and moderating both inputs and outputs, it helps ensure that AI systems are ethical, safe, and non-harmful. As AI continues to play a larger role in our daily lives, having robust safety systems like LlamaGuard in place will be crucial for building trust and maintaining a safe online environment.
