In today’s data-driven world, businesses generate large amounts of raw data daily. Transforming this raw data into meaningful insights requires effective data processing workflows, where ETL (Extract, Transform, Load) plays a crucial role. ETL simplifies the movement and transformation of data, empowering organizations to make informed decisions and gain a competitive edge. This blog dives into ETL, its importance, and its role in streamlining modern data workflows.
What is ETL?
ETL stands for Extract, Transform, Load, a process used to move data from multiple sources, clean and transform it, and load it into a target system, like a database or data warehouse as shown in the figure below.

Following are the stages of ETL automation.
- Extract: Data is collected from diverse sources such as databases, APIs, or IoT devices.
- Transform: The raw data is cleaned, validated, and formatted to align with the target schema.
- Load: The processed data is stored in a central repository, enabling easy access for analysis.
Common ETL Tools and Frameworks
The tools which are required for ETL are listed below.
- AWS Glue: A serverless ETL service for automating data preparation tasks.
- Talend: Open-source ETL software for integration and transformation.
- Apache Nifi: Real-time ETL for data streaming.
- Informatica: Enterprise-grade ETL for large-scale workflows.
What is a Job in ETL?
An ETL job is a unit of work that defines specific tasks in the ETL process. It specifies what data to extract, how to transform it, and where to load it.
Types of ETL Jobs
ETL jobs can handle different data processing requirements.
- Batch Jobs: Process large volumes of data in scheduled intervals.
- Real-Time Jobs: Handle streaming data continuously for instant updates.
- Incremental Jobs: Extract only new or modified data, optimizing performance.
Job is required to automate the ETL process.
Use Cases of ETL
ETL is integral to various industries and applications. Here are some prominent use cases:
1. Business Intelligence and Analytics
- Transform raw data into actionable insights for better decision-making.
- Create comprehensive dashboards for KPIs and trends.
2. Data Warehousing
- Consolidate data from multiple sources into a central repository.
- Enable seamless querying and reporting across unified datasets.
3. Cloud Data Migrations
- Simplify the movement of on-premises data to cloud platforms like AWS, Azure, or Google Cloud.
- Ensure compatibility and consistency during migration.
4. Operational Automation
- Streamline workflows like customer segmentation, product recommendations, or fraud detection.
- Enhance operational efficiency through automated data pipelines.
Let’s see the simple demo of ETL.
ETL Job Demo
In this demo, we illustrate how to transform data stored in a CSV format into a JSON format using AWS Glue, a serverless ETL service. The Workflow is shown in figure below.

The process involves creating a database in AWS Glue, setting up an ETL job to extract data from Amazon S3, applying the transformation, and loading the processed data back into S3. The resulting JSON file can then be accessed for analysis or further processing, showcasing the power and efficiency of automated ETL workflows.
The steps are given below:
- Create an S3 bucket to store CSV file
- Create Database
- Create an ETL Job
- Run the Job
- Retrieve data in JSON format
Create an S3 Bucket
Our first step is to create an S3 bucket to store our CSV file.
- Search S3 bucket from Amazon console & create bucket (lsdwebinar1)
- Create folders:
- raw-data
- source
- houses
- Add house_price.csv file in sources/houses folder
Next, we’ll create Database to store .csv data in proper format.
Create Database
- Go to Amazon Glue and Add Database (houseprice)

- No table in Database as we can see in below screenshot.
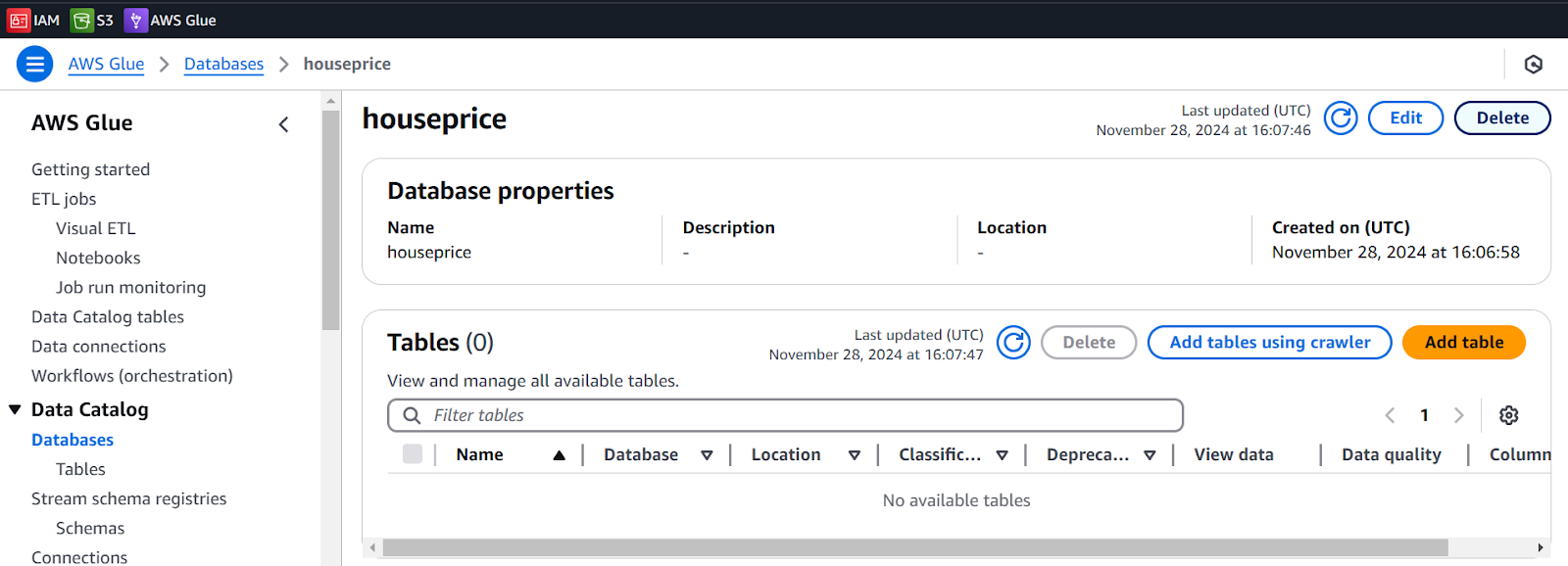
Let’s create an ETL job from AWS Glue.
Create an ETL Job
job is creating by two nodes: source node and target node. We can schedule jobs on demand or specify the desired frequency, such as every day at a particular time or every few hours. This will automate the process of ETL.
Here are the steps to create ETL job.
- Navigate to ETL Jobs in AWS Glue
- Create a job from blank graph/ visual ETL
- Add source node (amazon s3) select from source option
- Configure this node (click on node in a graph)
- Enter URL of the source/ browse s3
- Select data format (csv)
- Configure this node (click on node in a graph)
- Click on plus sign to Add target node(amazon s3) select from target option
- Configure this node (click on node in a graph)
- Node parent is already created
- Format (json)
- Compression(none)
- Target location raw-data / browse s3
- Data catalog update option: Create a table in the Data Catalog and on subsequent runs, update the schema and add new partitions
- Choose db(houseprice)
- Give name to the table which will create (data-house)
- Configure this node (click on node in a graph)
- Specify name to the job (csvtojson)
- Click on Job Details
- Request number of workers default 10, Use lowest possible number of worker 2
- Choose existing IAM role (AWSGlueServiceRole-glue-crawler-test), updated IAM role to access S3 bucket or create a new role with appropriate permissions.
- Keep other things as default
- Save this job
Screenshots:
Choose the correct location of S3 source node while configuring the node
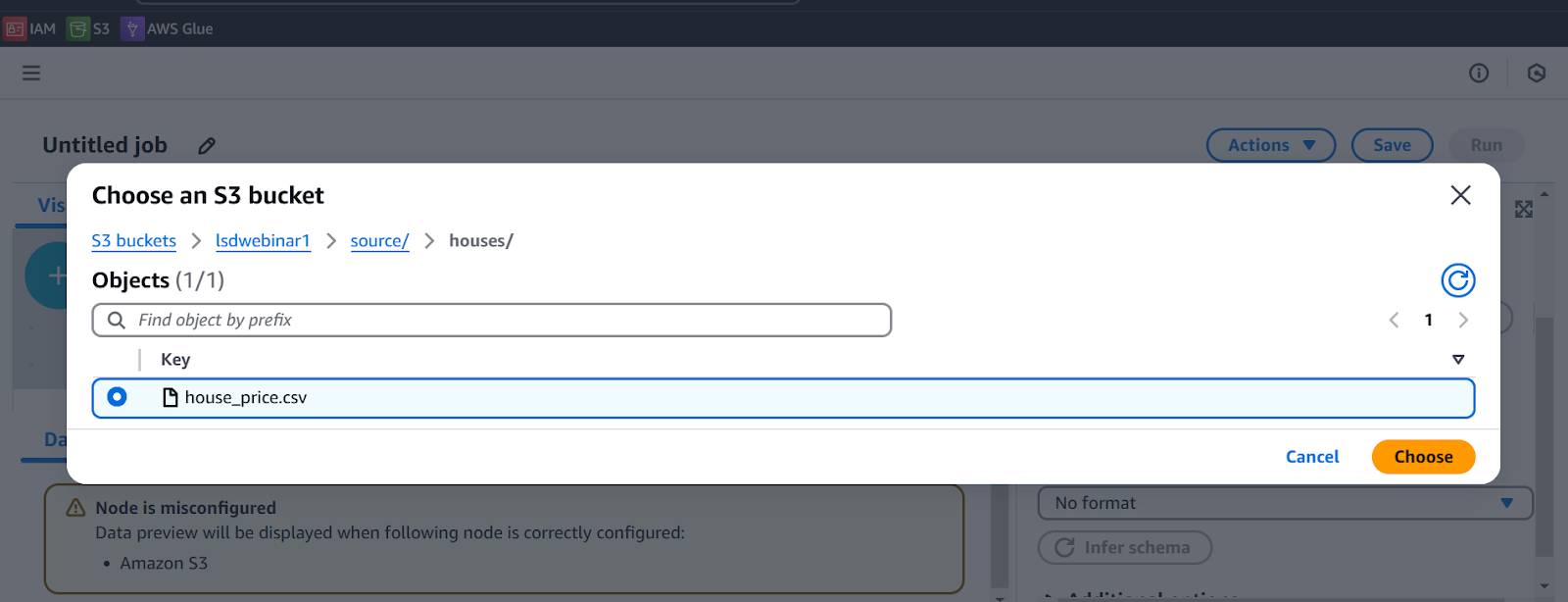
Choose the correct location of S3 target node while configuring target node
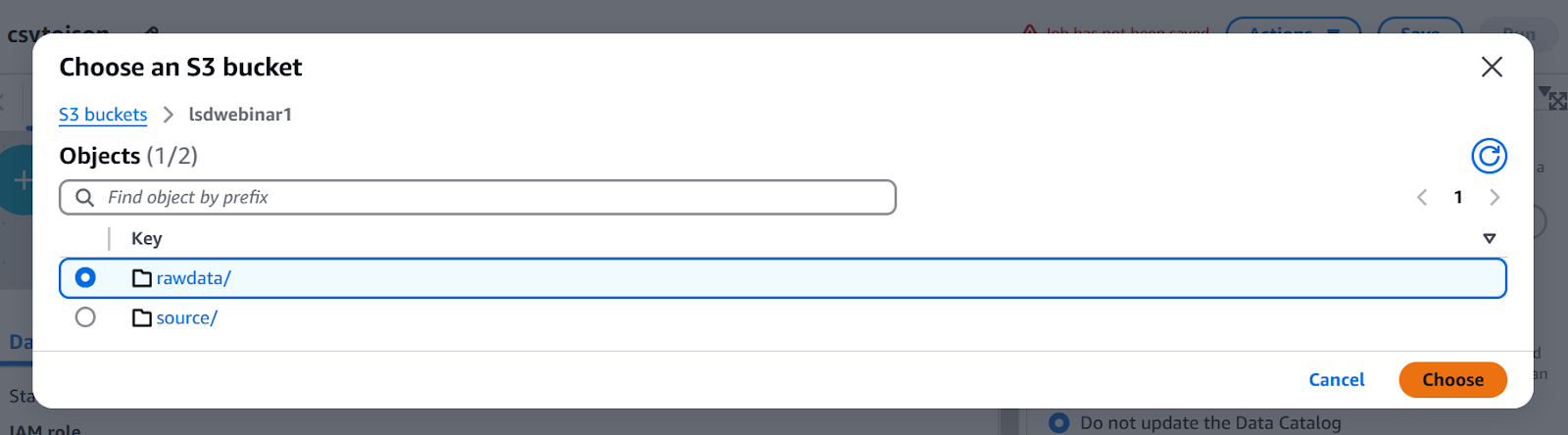
Run ETL Job
We are ready to run the job!
- Go to the ETL jobs select job (csvtojson) Click on Run
- Check run details to see the status
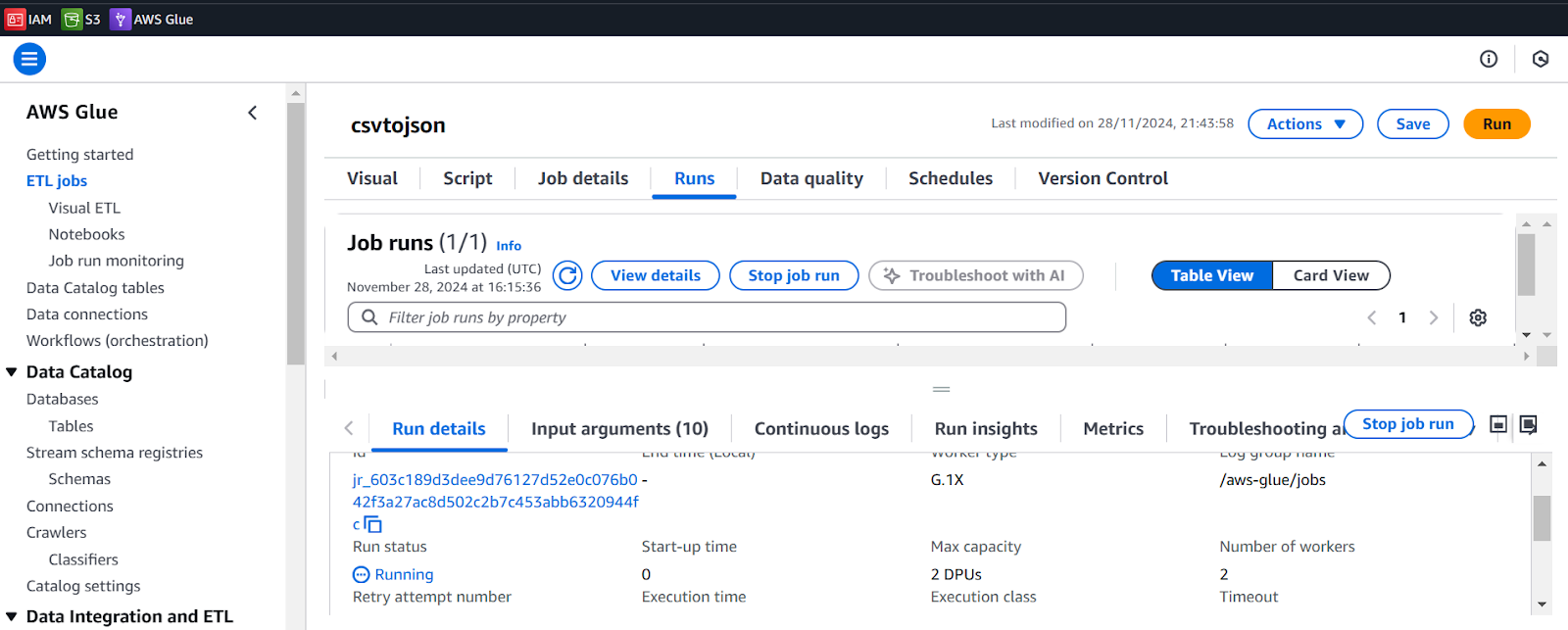
Navigate to S3 and verify if the file is available in (raw-data) folder. We can open it and save on the local machine. We can change the format any time by reconfiguring the target node.
Go to Database and check if the table is available or not? Yes it is!
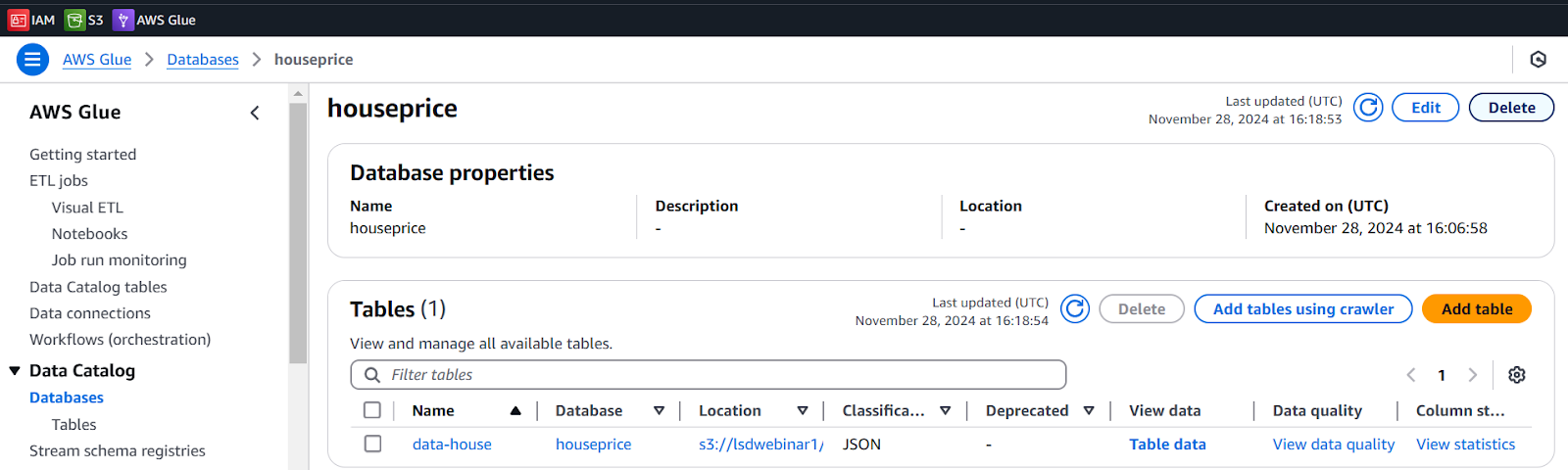
The table is created from a csv file.
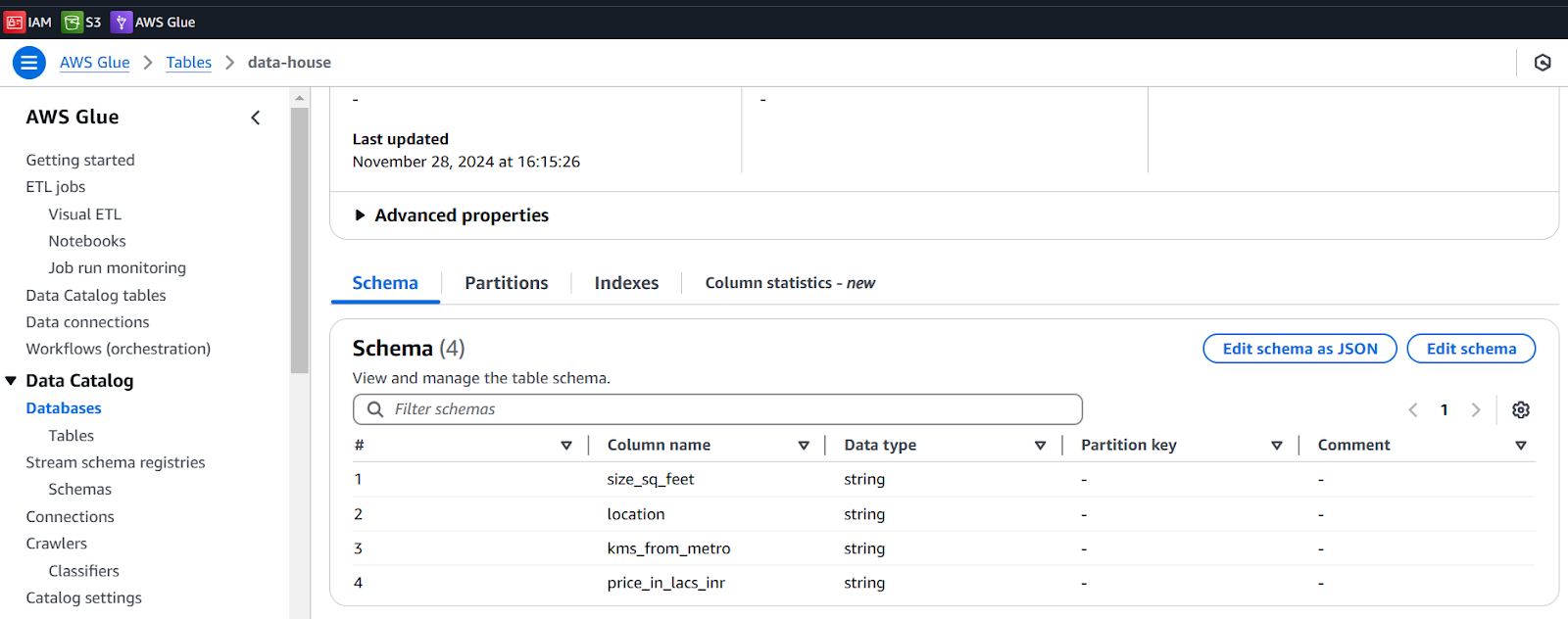
Our last step is to retrieve data in JSON format.
Retrieve Data in JSON Format
Now go to S3 bucket and navigate to our rawdata folder. here we can see new object is created.
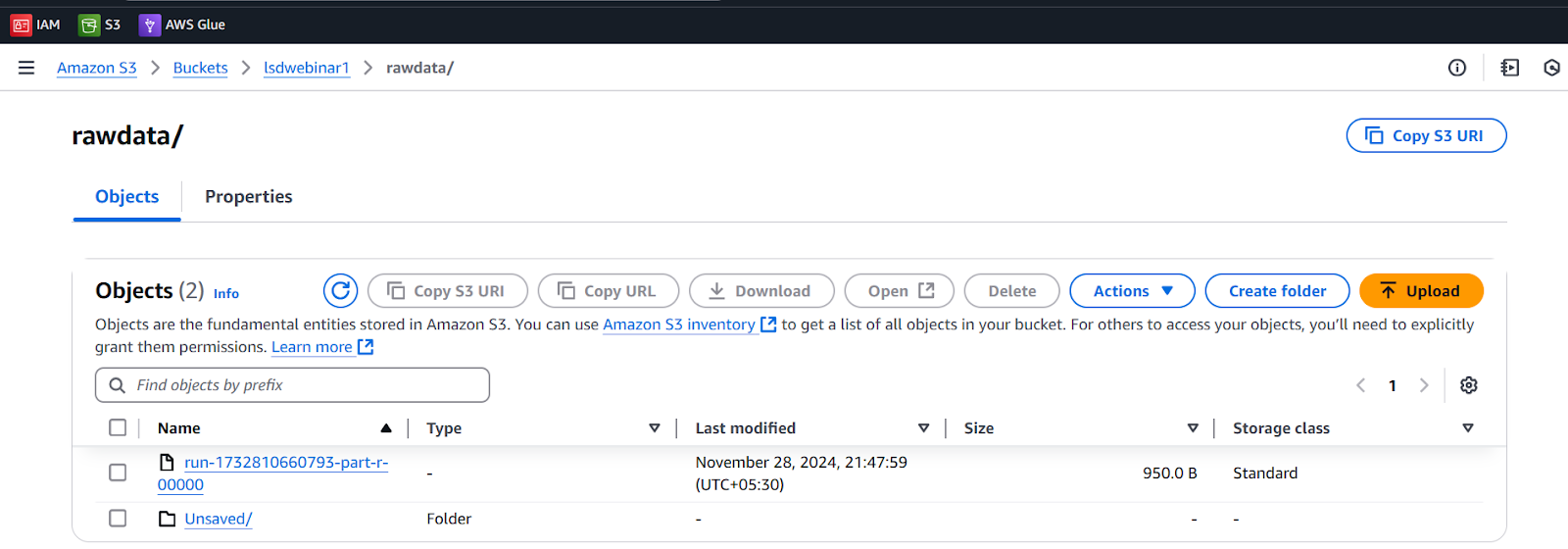
Open that newly created object that is our JSON file.
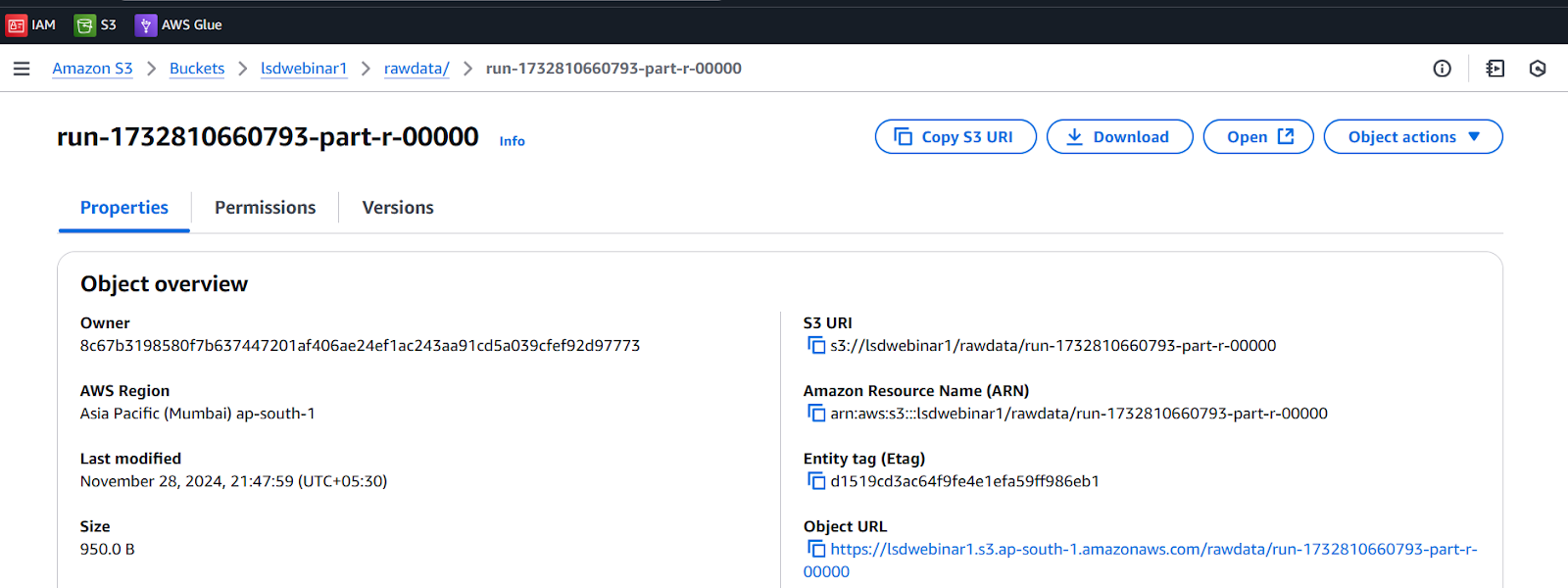
Click on open, we can see the JSON format of the file as below.
Conclusion
ETL is the backbone of modern data workflows, making raw data usable for business intelligence, analytics, and machine learning. By automating extraction, transformation, and loading tasks through ETL jobs, businesses can unlock the true potential of their data, driving innovation and growth. Whether you’re managing a data warehouse, migrating to the cloud, or building real-time analytics, ETL is the foundation for data success.
